



Los Datos, Ciencia, Ingeniería y Profesión
Por Francisco Ruiz y Mario Piattini (Catedráticos de Universidad).
Dicen que solo nos acordamos de Santa Bárbara cuando truena. Esto fue evidente en España, al igual que en casi todos los países, cuando, en los inicios de la pandemia de COVID, los gobiernos no pudieron disponer de datos adecuados para conocer la situación y tomar decisiones mejor fundamentadas. Tuvieron que pasar varios meses para que las autoridades empezaran a tener sistemas que les facilitaran los datos, en la forma y tiempo adecuados. Y, aun así, su credibilidad y exactitud no han sido admitidas de forma generalizada.
Datos, Información y Conocimiento se suelen usar como sinónimos, pero no lo son. Los Datos son los valores en bruto, la materia prima. Cuando se encuadran en un contexto reciben el nombre de información. Por último, el conocimiento es la información en forma y contexto útiles para ciertos fines. Por ejemplo, “195” es un dato en bruto, “Luis mide 195 cm” es información, y “Luis es una persona alta porque mide 195 cm” es conocimiento.
Los Datos pueden ser útiles para, a partir de ellos, generar nuevo conocimiento y/o tomar mejores decisiones, y así poder optimizar costes, ofrecer mejores servicios a los ciudadanos, atender mejor los intereses y necesidades de nuestros usuarios o clientes, o “mejorar por dentro para que se note por fuera” (mejora de procesos). En los últimos años, gracias al desarrollo de la tecnología informática, esta relevancia ha crecido hasta el punto de que se considera que los datos son una especie de nueva fuente de riqueza, para los individuos, las organizaciones o los países. Su recopilación y análisis es clave para lograr nuevos descubrimientos y cambios beneficiosos como, por ejemplo, combatir más eficazmente una pandemia, conocer la calidad del aire en cada ciudad y zona para tomar medidas adecuadas o conocer la situación del tráfico en tiempo real para poder adoptar de forma rápida medidas que eviten o reduzcan los atascos. Las posibilidades son infinitas, pero entre ellas también las hay con consecuencias potencialmente negativas. Por ese motivo los profesionales de los Datos deben estar imbuidos de un fuerte sentido de la responsabilidad y de la ética profesional.
Los Datos tienen su Ciencia y su Ingeniería, pero no hay consenso en la definición de Ciencia de Datos y, por tanto, tampoco en sus límites con la Ingeniería de Datos.
Para aclararlo tomamos las palabras de Theodore von Kármán, prestigioso físico e ingeniero húngaro-estadounidense: “los científicos estudian el mundo como es mientras que los ingenieros crean el mundo que nunca antes ha sido”. En otras palabras, el objetivo de la Ciencia es conocer la realidad, mientras que el de la ingeniería es cambiarla creando nuevos artefactos tecnológicos. Aplicado al mundo físico, podemos deducir que estudiar los agujeros negros del universo es Ciencia, mientras que diseñar y construir el telescopio para estudiarlos es Ingeniería. De forma similar, aplicado a los Datos, podemos derivar que la Ciencia de Datos busca obtener nuevo conocimiento a partir de los datos mientras que la Ingeniería de Datos busca cambiar la realidad usando datos. Una definición, más elaborada y acotada, la podemos obtener en el “Cuerpo de Conocimientos sobre Gestión de Datos” (Data Management Body of Knowledge), elaborado por DAMA (https://www.dama.org), la asociación internacional de profesionales en gestión de datos. DAMA asocia la Ciencia de Datos con intentar predecir el futuro, al definirla como “construir modelos predictivos que exploran patrones contenidos en los datos”. Y para ello “combina minería de datos, análisis estadístico y aprendizaje automático con capacidades de integración y modelado de datos” y “sigue el método científico para mejorar el conocimiento mediante formulación y verificación de hipótesis, observando resultados, y formulando teorías generales que expliquen los resultados”.
En la vida real los objetivos de la Ciencia de Datos y los de la Ingeniería son, muchas veces, inseparables ya que, para poder obtener nuevo conocimiento de los datos (Ciencia), antes es necesario diseñar y crear sistemas tecnológicos que los almacenen y procesen en forma adecuada (Ingeniería).
Incluso es frecuente que la misma persona unas veces esté haciendo Ciencia de Datos y otras Ingeniería de Datos. Por ello es más conveniente hablar de “Ciencia e Ingeniería de Datos”, incluyendo ambas, como la disciplina enfocada en obtener valor de los Datos gracias a las tecnologías de la información (TI).
Para poder sacar provecho adecuado de los datos son necesarios conocimientos y competencias diversos. La principal referencia a nivel internacional para saber cuáles son es la propuesta de ACM (Association for Computer Machinery, la asociación más prestigiosa a nivel internacional en el campo de la informática), conocida como “Computing Competencies for Undergraduate Data Science Curricula” (disponible en https://www.acm.org/education/curricula-recommendations). En ella se identifican las siguientes once áreas de conocimiento y competencia (dejamos las siglas originales en inglés): Análisis y presentación de datos (AP); Inteligencia Artificial (IA); Sistemas de Big Data (BDS); Fundamentos de computación e informática (CCF); Adquisición, gestión y gobierno de datos (DG); Minería de datos (DM); Privacidad, seguridad, integridad y análisis para la seguridad de los datos (DP); Aprendizaje automático (ML); Profesionalidad (PR); Programación, estructuras de datos y algoritmos (PDA); y Desarrollo y mantenimiento de software (SDM). Algunas de ellas son comunes a otras disciplinas dentro de la Informática y las TI. Otras están especialmente enfocadas a las responsabilidades de los profesionales en Ciencia e Ingeniería de Datos, como es el caso de Análisis y presentación de datos; Sistemas de Big Data; Adquisición, gestión y gobierno de datos; y Minería de datos.
Otra fuente relevante es la ya mencionada asociación DAMA, que aporta un enfoque centrado en gestión de datos (parte de la Ingeniería de Datos). Los conocimientos y competencias relevantes que ha identificado se agrupan en las áreas mostradas en la Figura 1.
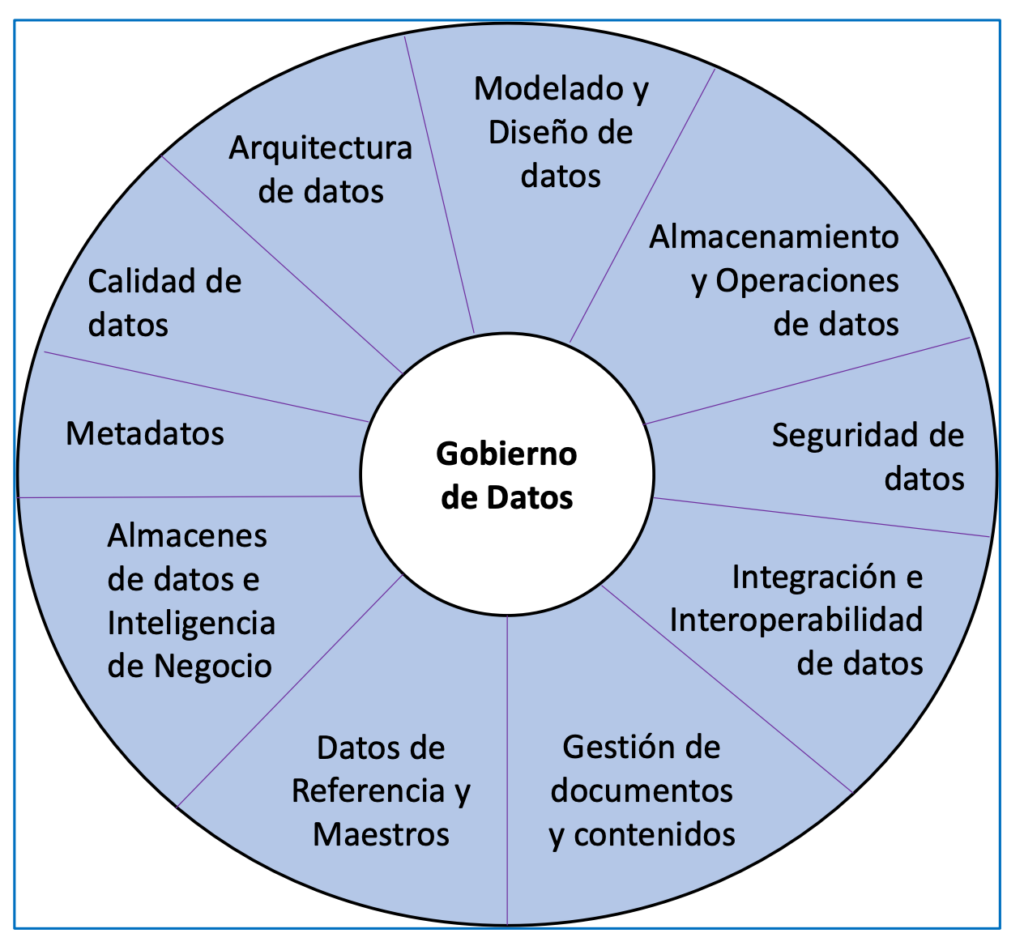
CEPIS (Consejo de sociedades informáticas profesionales europeas) establece que un buen profesional es una persona que combina conocimientos, competencias, formación, responsabilidad y ética para ser capaz de aportar valor a otras personas.
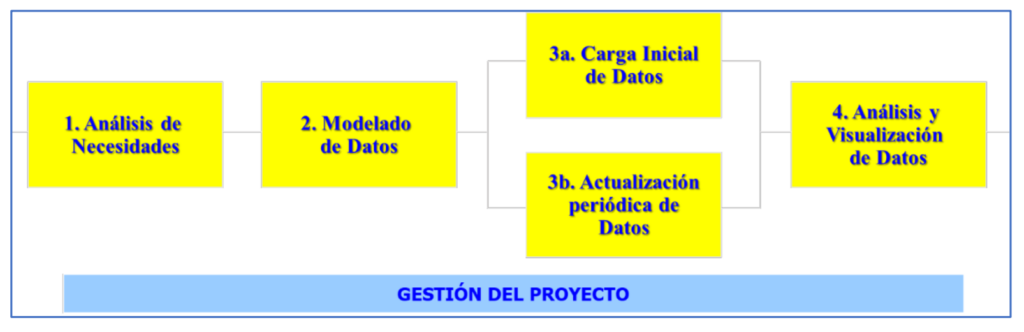
Las dos colecciones de competencias y conocimientos anteriores son un buen punto de partida para delimitar la profesión de Ciencia e Ingeniería de Datos, cuyo fin es extraer valor de los datos. Por tanto, la valía de un profesional de esta disciplina se debe medir por su capacidad de obtener, a partir de los datos, valor para otras personas y organizaciones o para la sociedad en general. Para lograr ese valor, los profesionales de los datos llevan a cabo esfuerzos y proyectos cuyo resultado final suele ser la creación de sistemas de información que permiten visualizar y analizar los datos, y poder extraer nuevo conocimiento de ellos. Esos proyectos se suelen llevar a cabo en las etapas mostradas en la Figura 2.
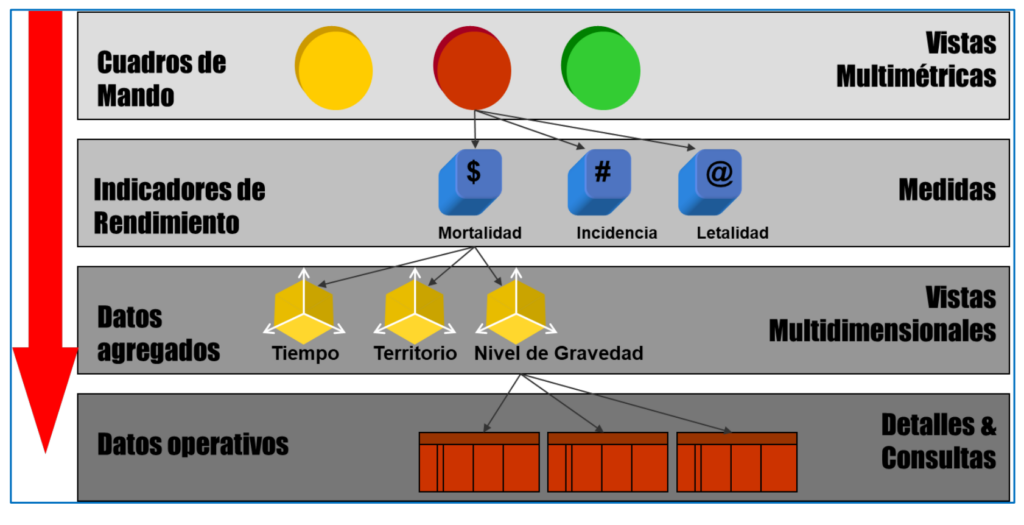
A lo largo de las diversas etapas de un proyecto, los expertos manejan Datos e Información a cuatro niveles diferentes, que se muestran en la Figura 3 con un ejemplo sobre datos de la pandemia de COVID. Se parte de los datos operativos en bruto (número de casos y defunciones cada día en cada localidad). Después, se necesita identificar las dimensiones para analizar los datos, por ejemplo, por tiempo (cuándo ocurre), territorio (dónde ocurre) y nivel de gravedad (qué ocurre). Eso requiere procesar los datos (normalmente usando herramientas software que implementan ciertos algoritmos) para agruparlos a los niveles de detalle adecuados para cada dimensión de análisis. Por ejemplo, en el caso del tiempo, por días, semanas y meses, o por localidades, provincias y comunidades autónomas en el caso de la localización territorial. A partir de esos datos agregados de la forma que se necesita, podemos pasar a calcular los indicadores relevantes para la toma de decisiones, por ejemplo, la incidencia acumulada cada semana en cada provincia (número de casos por cada 100 mil habitantes). Por último, los valores de los indicadores y demás datos se suelen facilitar a los no informáticos mediante sistemas de información (“cuadros de mando” y otros tipos) que facilitan la visualización y análisis de los datos para la toma de decisiones. En https://alarcos.esi.uclm.es/covid19esp/ se muestra un ejemplo con datos reales del COVID.
A continuación, se presentan algunos aspectos relevantes de las etapas en proyectos de valorización de datos (Figura 2).
En primer lugar, hay que conocer las necesidades. En un proyecto de Datos esto se centra en identificar qué medir y cómo medirlo de forma adecuada y, a partir de ello, encontrar las fuentes donde podemos obtener los Datos necesarios para ello.
En la etapa segunda se aborda un aspecto clave para trabajar con Datos: darles una estructura y forma adecuada para poder almacenarlos en los ordenadores y poder hacer con ellos todo lo que queremos. Esa tarea puede ser tan relevante para el éxito de un proyecto de Datos como lo es para un proyecto de construcción “hacer bien los planos del edificio”. En este asunto resulta útil la noción genérica de arquitectura (definida en estándar ISO 42010). Así, la ‘arquitectura de los datos’ establece los elementos o compartimentos en que los separamos (tablas, ficheros, etc.) y las relaciones entre dichos elementos. También se necesita definir bien la estructura interna de cada compartimento (qué datos concretos guarda) y el tipo o naturaleza (número, fecha, texto, audio, video, documento, …) de cada dato concreto. El modelado de datos consiste en ‘crear los planos’ con una arquitectura y estructura de datos adecuadas para las necesidades del proyecto. Esos planos se pueden expresar en forma de esquemas entidad-relación, relacionales o multidimensionales.
Pasar de los datos en bruto a los datos preparados para poder ser analizados puede ser una tarea bastante compleja. Es parecido a lo que sucede con el agua, que para que sea apta al consumo humano debe sufrir varias transformaciones desde la fuente de donde surge, y para lo que hay que construir además diferentes tipos de canalizaciones y tuberías. Así, es necesario identificar todas las fuentes de los datos originales, desde ficheros informáticos ya disponibles con estructura clara (CSV, Excel, etc.) hasta datos en formatos poco estructurados como la web o redes sociales. Los procesos ETL, por las siglas inglesas de extracción, transformación y carga, consisten en: i) descargar los datos en bruto de las fuentes originales; ii) transformarlos a unos formatos y estructuras adecuados y homogéneos; y iii) integrarlos en un repositorio o almacén de datos, basado en la arquitectura de datos establecida previamente. Para hacer ETL se pueden usar tecnologías tradicionales (como SQL), pero se puede ser más productivo usando otras ideadas especialmente para ello (Power Query, Big Query, etc.). Una alternativa en los últimos años es usar un lago de datos (datalake). Se trata de una tecnología que evita crear un almacén integrado de datos y lo sustituye por una colección de datos heterogéneos, que conservan su formato original, pero que se almacenan en un mismo sistema informático. Para garantizar acceso común e integrado son necesarios metadatos (datos sobre los datos).
Una necesidad del profesional de la Ciencia e Ingeniería de Datos, fuertemente relacionada con el modelado de datos es saber manejar la tecnología informática para almacenar y procesar Datos de forma eficiente y eficaz.
Sin ello es imposible realizar la tercera etapa de los proyectos de valorización de datos (Figura 2). El antes mencionado repositorio de datos se puede hacer con dos tipos de tecnologías: sistemas de gestión de bases de datos (tradicionales relacionales como ORACLE, MySQL, etc.; o no relacionales como MongoDB) y herramientas para Big Data (Hadoop, Elasticsearch, etc.). Las últimas sustituyen a las primeras cuando se necesita trabajar con cantidades masivas de datos, permitiendo abordar retos del manejo de Datos conocidos como las 7 Vs del Big Data: volumen, velocidad, variedad, veracidad, viabilidad, visualización y valor de los datos. Otra opción, normalmente emparejada con Big Data, son las tecnologías de lagos de datos, antes mencionados.
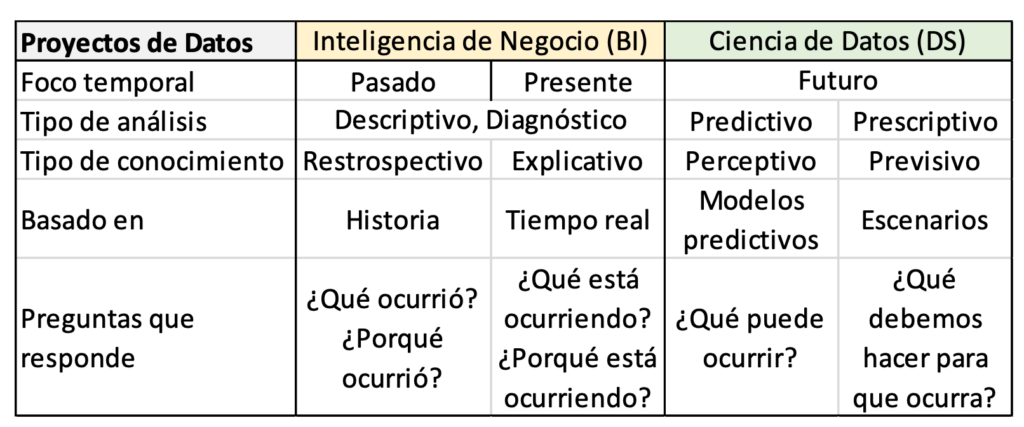
Una vez creado y poblado el repositorio o su equivalente, en la cuarta etapa es cuando realmente se saca valor de los datos mediante su análisis y visualización. Para ello, lo primero es conocer los tipos de Análisis de Datos que se pueden realizar, según los tipos de preguntas que se quieran responder: descriptivo (¿Qué ha ocurrido?), diagnóstico (¿Por qué ha ocurrido?), predictivo (¿Qué es probable que ocurra en adelante?) y prescriptivo (¿Cuál es la mejor opción para seguir?). Cada tipo de análisis se basa en un tipo de técnicas matemáticas (estadística, métodos numéricos) o informáticas (aprendizaje automático, minería de datos, etc.). Es importante conocer el tipo de análisis y técnicas concretas que son útiles para cada situación, ya que eso es lo que determinará las herramientas que podemos usar para hacerlo. Por ejemplo, para averiguar si hay más incidencia del virus en las ciudades o en las zonas rurales se puede realizar un análisis descriptivo empleando estadística básica tradicional. En cambio, para saber cuándo es probable que ocurra la próxima ola de virus podemos emplear aprendizaje automático y/o minería de datos. Según los tipos de análisis que se realizan, las iniciativas de valorización de datos se pueden distinguir entre proyectos de Ciencia de Datos o proyectos de Inteligencia de Negocio (BI, Business Intelligence). La palabra ‘negocio’ en los segundos refiere a hacer lo adecuado para que una organización alcance sus objetivos. La Tabla 1 resume las diferencias principales entre ellos. Esa separación no existe muchas veces en la realidad porque los proyectos combinan varios tipos de análisis, siendo a la vez de Ciencia de Datos y de Inteligencia de Negocio. También es frecuente que las necesidades y tipos de análisis no se conozcan completamente a priori o se cambien en función de la evolución del proyecto.
Aprendizaje automático, o aprendizaje máquina (machine learning), es un grupo de técnicas que sirven para descubrir patrones en los datos y hacer predicciones. Engloba árboles de decisión, regresión lineal, agrupamiento (clustering) y redes neuronales, entre otras. Su nombre proviene de que algunas de ellas, caso de redes neuronales, se basan en imitar cómo aprende el cerebro humano. Existen muchas herramientas software para facilitar su realización, tales como TensorFlow, Cloud AutoML o Azure ML.
El nombre minería de datos evidencia similitud con la minería tradicional. Efectivamente, la minería física emplea técnicas para extraer una pequeña porción valiosa procesando cantidades inmensas de tierra del suelo y la segunda extrae información de valor procesando grandes cantidades de datos. Existen múltiples tecnologías para hacer minería de datos. Algunas son herramientas especializadas, como RapidMiner. También existen los lenguajes de programación como R y DAX. Otras son de propósito general, como el lenguaje Python. Un caso especial es la minería de procesos de negocio, muy relevante para la transformación digital de las organizaciones, ya que analiza datos que reflejan todo lo relevante que ocurre en los procesos internos de una organización (vender, almacenar, fabricar, atender pacientes, etc.) y, a partir de ellos, obtiene información para cambiar a mejor (análisis prescriptivo) la forma de llevar a cabo los procesos.
Como complemento al análisis de datos, muchos proyectos incluyen visualizarlos de forma adecuada (fila superior en la Figura 3). La Visualización de Datos puede ser muy relevante para aportar valor, facilitando la consulta y comprensión a los responsables que deben tomar las decisiones. Existen herramientas software especializadas que permiten obtener sistemas en los cuales la interfaz del usuario sea muy visual e interactiva gracias a usar patrones de interacción predefinidos. Es el caso de herramientas como Tableau o Power BI (la Figura 4 muestra su uso para crear el ejemplo con datos del COVID). Algunas herramientas, como Power BI, incluyen facilidades para todas las etapas de los proyectos de Datos, desde la descarga de datos de las fuentes hasta análisis de diversos tipos y la visualización. Se las conoce como plataformas ABI (Analytics and Business Intelligence).
Una vez un proyecto de Datos ha sido completado (concluidas todas las etapas de la Figura 2), se entra en la explotación de sus resultados. En ese momento entran en juego otros conocimientos y competencias de los profesionales de los Datos. Los datos son un activo muy valioso y estratégico y, por ello, es relevante implantar prácticas para garantizar que la organización dispone de los datos que necesita, cuando, cómo y con la calidad y seguridad adecuados. El Gobierno de Datos establece la estrategia para atender esas necesidades organizacionales (ejemplo: cumplir el reglamento europeo de protección de datos personales) y la Gestión de Datos implementa prácticas concretas para cumplirlas, por ejemplo, cómo evitar silos aislados de datos en los distintos departamentos de la empresa. Otros aspectos que los profesionales de los Datos deben tener siempre en mente son: la Calidad (exactitud, precisión, etc.), la Seguridad en todas sus dimensiones de integridad, confidencialidad y disponibilidad; y la Privacidad cuando se trata de datos personales. ¿Cómo aseguro que no haya datos duplicados con valores diferentes? ¿Quién puede acceder a cada dato? o ¿Cómo elimino o rebajo riesgos de pérdida de datos? son preguntas que necesitan ser respondidas correctamente por los profesionales de los Datos.
Hemos presentado las principales competencias y conocimientos informáticos que se pueden requerir en un proyecto centrado en Datos. Son muy amplios y es difícil que una misma persona reúna todos con suficiente profundidad. Por ello, puede ser conveniente establecer perfiles profesionales diferentes. Es lo que hace la norma “European ICT Professional Role Profiles” (https://itprofessionalism.org/about-it-professionalism/competences/ict-profiles/), que distingue entre Científico de Datos (Data Scientist), Especialista en Datos (Data Specialist) y Administrador de Datos (Data Administrator). El primero se centra, sobre todo, en el análisis de los datos, el segundo en los aspectos de modelado y gobierno de los datos, y el tercero en la gestión de los repositorios de datos y su seguridad.
Un último aspecto que destacar en la profesión de Ciencia e Ingeniería de Datos es que los proyectos pueden ser multidisciplinares. Además de perfiles con los conocimientos y competencias presentados en este artículo, en bastantes proyectos es necesario contar con otros perfiles no informáticos, especialmente expertos en el dominio de aplicación y matemáticos/estadísticos.
Los expertos en el dominio de aplicación son las personas que conocen muy bien el campo de aplicación de los datos (por ejemplo, expertos en salud pública y epidemias) y por ello son las que saben bien qué interesa medir y con qué indicadores se deben tomar las decisiones. Su papel al principio del proyecto es clave para la identificación de las necesidades y para conocer las fuentes de datos existentes. Por otro lado, esos expertos del dominio son los futuros usuarios de los sistemas desarrollados en los proyectos de Datos y, por ello, es muy deseable que participen en validar los resultados. Los matemáticos/estadísticos pueden contribuir con un conocimiento más profundo de algunas de las técnicas de análisis para el caso de datos cuantitativos numéricos.
Los Datos tienen su Ciencia y su Ingeniería. La gran importancia que tienen requiere de profesionales, en Ciencia e Ingeniería de Datos, que sepan llevar a cabo los proyectos que aporten valor a las organizaciones y a la sociedad.
Francisco Ruiz (francisco.ruizg@uclm.es)
Mario Piattini (Mario.piattini@uclm.es)


