



Data, Science, Engineering and Profession
By Francisco Ruiz y Mario Piattini (University Professors).
They say we only remember Santa Barbara when it thunders. This was evident in Spain, as in almost all countries, when, at the beginning of the COVID pandemic, governments could not have adequate data to understand the situation and make better-informed decisions. Several months had to pass before the authorities began to have systems that provided them with the data, in the appropriate form and time. And yet its credibility and accuracy have not been widely accepted.
Data, Information and Knowledge They are often used as synonyms, but they are not. Data is the raw values, the raw material. When they are framed in a context they are called information. Finally, knowledge is information in a form and context useful for certain purposes. For example, "195" is raw data, "Luis is 195 cm" is information, and "Luis is a tall person because he is 195 cm" is knowledge.
The Data can be useful for, from them, generating new knowledge and/or making better decisions, and thus be able to optimize costs, offer better services to citizens, better serve the interests and needs of our users or clients, or "improve inside so that it is noticed on the outside” (process improvement). In recent years, thanks to the development of information technology, this relevance has grown to the point that data is considered a kind of new source of wealth, for individuals, organizations or countries. Its collection and analysis is key to achieving new discoveries and beneficial changes, such as combating a pandemic more effectively, knowing the air quality in each city and area to take appropriate measures or knowing the traffic situation in real time to be able to adopt measures to prevent or reduce traffic jams quickly. The possibilities are endless, but among them there are also those with potentially negative consequences. For this reason, Data professionals must be imbued with a strong sense of responsibility and professional ethics.
Data has its Science and Engineering, but there is no consensus on the definition of Data science and, therefore, neither in its limits with the Data Engineering.
To clarify it, we take the words of Theodore von Kármán, a prestigious Hungarian-American physicist and engineer: “lcientists study the world as it is while engineers create the world that has never been before. In other words, the objective of Science is to know reality, while that of engineering is to change it by creating new technological artifacts. Applied to the physical world, we can deduce that studying the black holes of the universe is Science, while designing and building the telescope to study them is Engineering. Similarly, applied to Data, we can derive that Data Science seeks to obtain new knowledge from data while Data Engineering seeks to change reality using data. A more elaborate and limited definition can be found in the "Body of Knowledge on Data Management" (Data Management Body of Knowledge), produced by DAMA (https://www.dama.org), the international association of data management professionals. DAMA associates Data Science with trying to predict the future, defining it as “building predictive models that explore patterns contained in data”. And for this it "combines data mining, statistical analysis and machine learning with data integration and modeling capabilities" and "follows the scientific method to improve knowledge by formulating and verifying hypotheses, observing results, and formulating general theories that explain the results".
In real life, the objectives of Data Science and Engineering are often inseparable since, in order to obtain new knowledge from data (Science), it is first necessary to design and create technological systems that store and process them. properly (Engineering).
It is even frequent that the same person is sometimes doing Data Science and other Data Engineering. For this reason, it is more convenient to speak ofData Science and Engineering”, including both, as the discipline focused on obtaining value from Data thanks to information technology (IT).
In order to take advantage of the data, it is necessary to diverse knowledge and skills. The main international reference to know what they are is the ACM proposal (Association for Computer Machinery, the most prestigious international association in the field of computing), known as "Computing Competencies for Undergraduate Data Science Curriculum" (available in https://www.acm.org/education/curricula-recommendations). It identifies the following eleven areas of knowledge and competence (we leave the original acronyms in English): Analysis and presentation of data (AP); Artificial Intelligence (AI); Big Data Systems (BDS); Computer and Informatics Fundamentals (CCF); Data acquisition, management and governance (DG); Data Mining (DM); Privacy, security, integrity and analysis for data security (DP); Machine Learning (ML); Professionalism (PR); Programming, data structures and algorithms (PDA); and Software development and maintenance (SDM). Some of them are common to other disciplines within Computing and IT. Others are especially focused on the responsibilities of professionals in Data Science and Engineering, as is the case of Analysis and presentation of data; Big Data Systems; Data acquisition, management and governance; and Data Mining.
Another relevant source is the aforementioned DAMA association, which provides an approach focused on data management (part of Data Engineering). The relevant knowledge and competencies that you have identified are grouped into the areas shown in Figure 1.
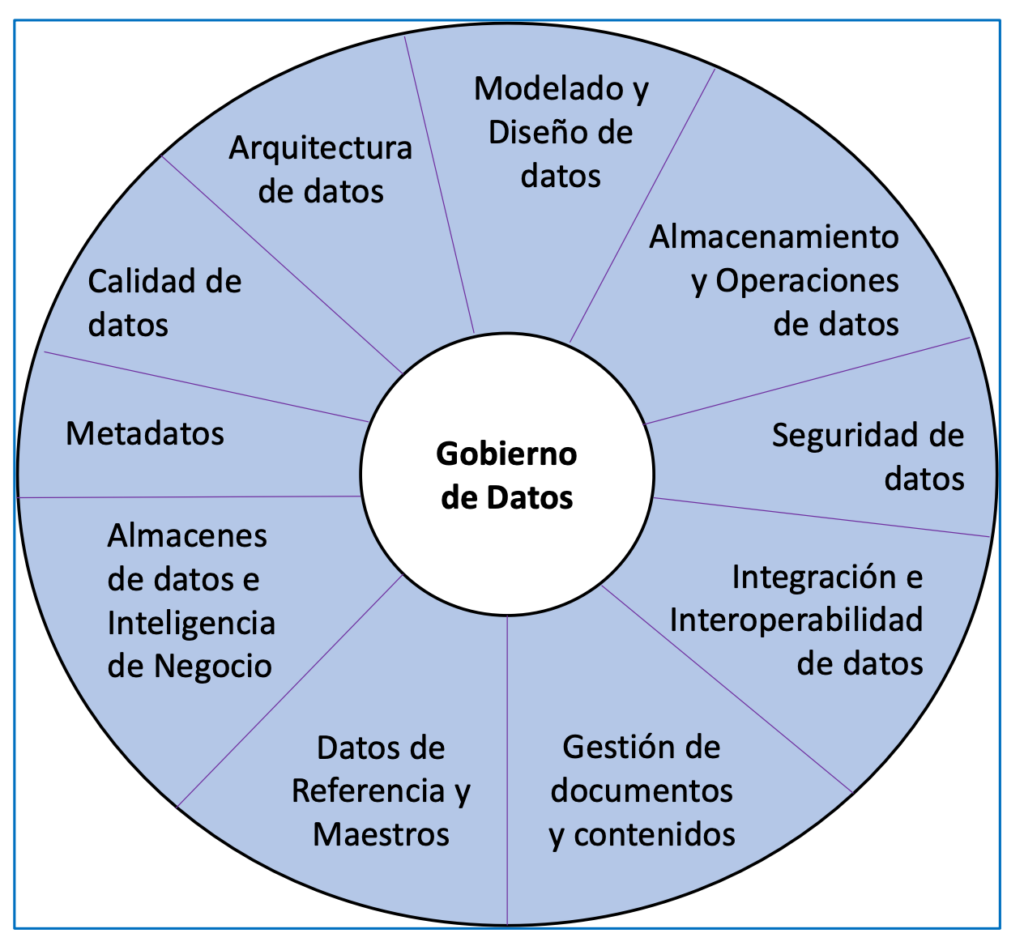
CEPIS (Council of European Professional Informatics Societies) establishes that a good professional is a person who combines knowledge, skills, training, responsibility and ethics to be able to add value to other people.
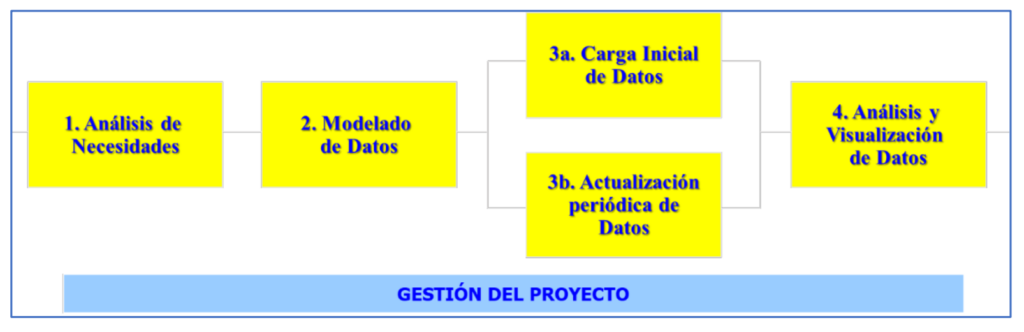
The above two collections of skills and knowledge are a good starting point for delimiting the Data Science and Engineering profession, whose purpose is to extract value from the data. Therefore, the value of a professional in this discipline must be measured by their ability to obtain value from data for other people and organizations or for society in general. To achieve that value, data professionals carry out efforts and projects whose final result is usually the creation of information systems that allow data to be visualized and analyzed, and to be able to extract new knowledge from it. These projects are usually carried out in the stages shown in Figure 2.
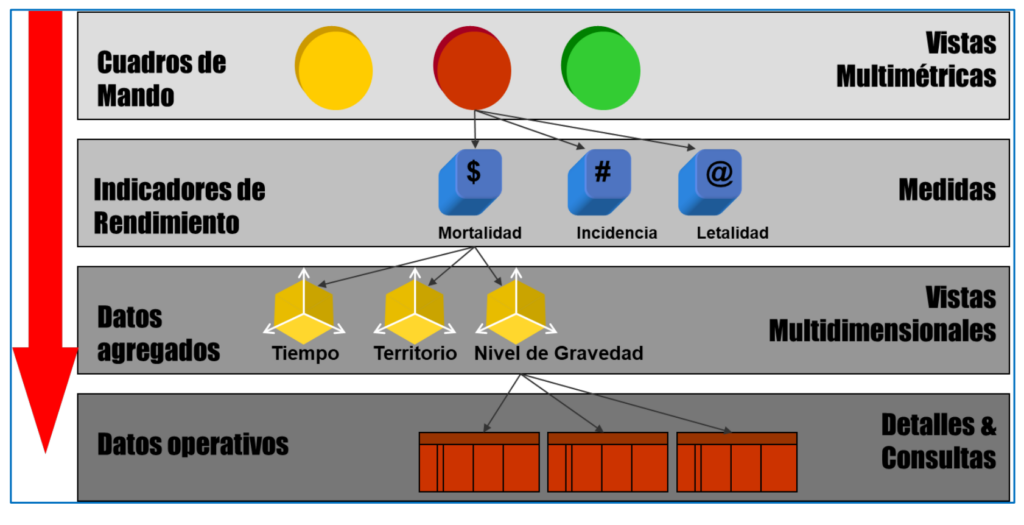
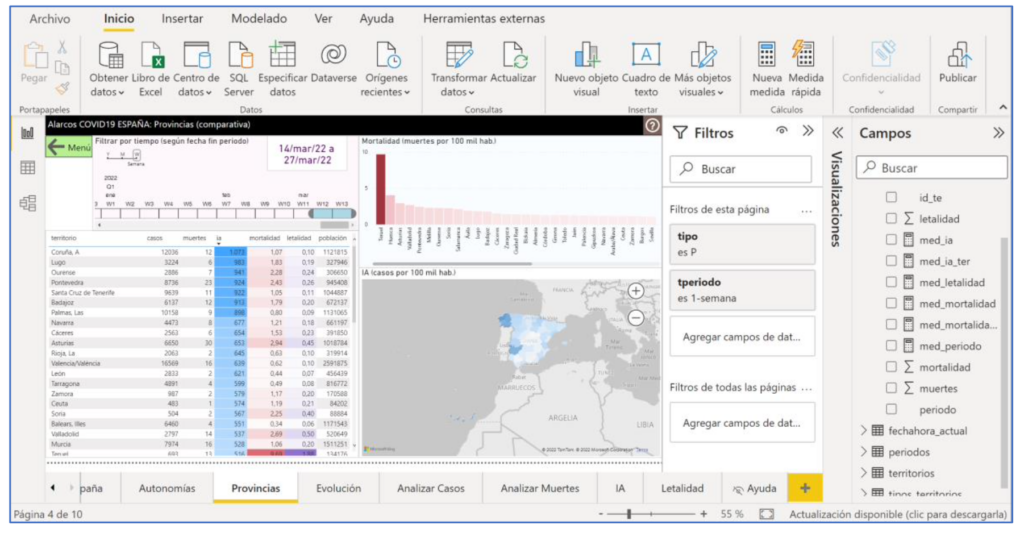
Throughout the various stages of a project, experts handle Data and Information at four different levels, shown in Figure 3 with an example on data from the COVID pandemic. It starts from the raw operational data (number of cases and deaths each day in each locality). Next, you need to identify the dimensions to analyze the data, for example, by time (when it happens), territory (where it happens) and level of severity (what happens). That requires processing the data (usually using software tools that implement certain algorithms) to group them to the appropriate levels of detail for each dimension of analysis. For example, in the case of time, by days, weeks and months, or by localities, provinces and autonomous communities in the case of territorial location. From these aggregated data in the way that is needed, we can proceed to calculate the relevant indicators for decision-making, for example, the cumulative incidence each week in each province (number of cases per 100 inhabitants). Finally, the values of the indicators and other data are usually provided to non-computers through information systems ("dashboards" and other types) that facilitate the visualization and analysis of the data for decision-making. In https://alarcos.esi.uclm.es/covid19esp/ An example is shown with real COVID data.
Some relevant aspects of the stages in data valorization projects are presented below (Figure 2).
First of all, you have to know the needs. In a Data project this focuses on identifying what to measure and how to measure it appropriately and, from this, find the sources where we can obtain the necessary Data for it.
In the second stage, a key aspect for working with Data is addressed: giving it an adequate structure and form to be able to store it on computers and be able to do everything we want with it. That task can be just as relevant to the success of a Data project as “getting the building plans right” is to a construction project. In this matter, the generic notion of architecture (defined in the ISO 42010 standard) is useful. Thus, the 'data architecture' Establishes the elements or compartments in which we separate them (tables, files, etc.) and the relationships between said elements. It is also necessary to define well the internal structure of each compartment (what specific data it stores) and the type or nature (number, date, text, audio, video, document,...) of each specific data. The data modeling it consists of 'creating the blueprints' with an architecture and data structure suitable for the needs of the project. These blueprints can be expressed in the form of entity-relationship, relational, or multidimensional schemas.
Going from raw data to data prepared for analysis can be quite a complex task. It is similar to what happens with water, which in order for it to be suitable for human consumption must undergo various transformations from the source from which it arises, and for which different types of pipes and pipes must also be built. Thus, it is necessary to identify all the sources of the original data, from already available computer files with a clear structure (CSV, Excel, etc..) to data in unstructured formats such as the web or social networks. The ETL processes, for extract, transform and load, consists of: i) downloading the raw data from the original sources; ii) transform them into appropriate and homogeneous formats and structures; and iii) integrate them into a repository or data warehouse, based on the previously established data architecture. To do ETL, you can use traditional technologies (such as SQL), but you can be more productive using others specially designed for this (Power Query, Big Query, etc.). An alternative in recent years is to use a data lake (data lake). It is a technology that avoids creating an integrated data store and replaces it with a collection of heterogeneous data, which retains its original format, but is stored in the same computer system. To guarantee common and integrated access, it is necessary Metadata (data about data).
A need of the Data Science and Engineering professional, strongly related to data modeling, is knowing how to handle the technology computing for store and process Data efficiently and effectively.
Without it, it is impossible to carry out the third stage of the data valorization projects (Figure 2). The aforementioned data repository can be done with two types of technologies: data management systems databases (traditional relational ones like ORACLE, MySQL, etc.; or non-relational ones like MongoDB) and tools for Big Data (Hadoop, Elasticsearch, etc.). The latter replace the former when it is necessary to work with massive amounts of data, allowing to address data management challenges known as the 7 Vs of Big Data: volume, speed, variety, veracity, feasibility, visualization and value of data. Another option, often paired with Big Data, is the aforementioned data lake technologies.
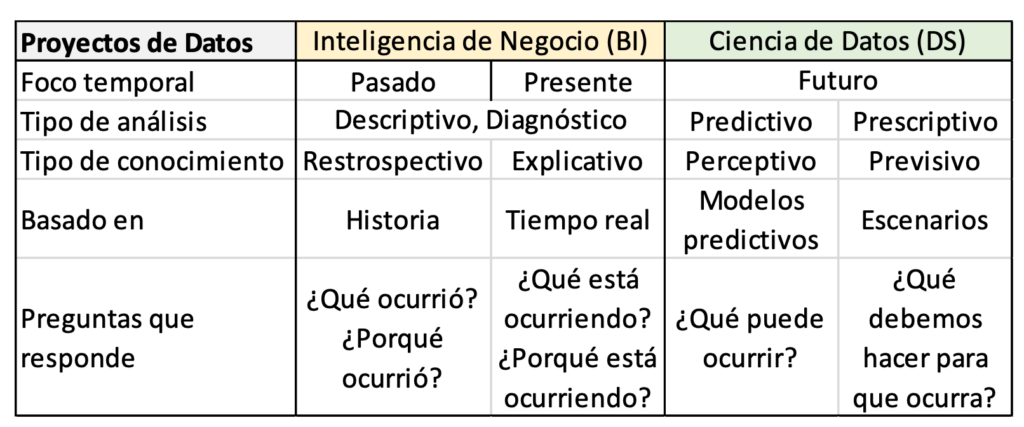
Once the repository or its equivalent has been created and populated, the fourth stage is when value is really extracted from the data through its analysis and visualization. To do this, the first thing is to know the types of Analysis of data that can be done, depending on the types of questions that you want to answer: descriptive (what happened?), diagnosis (Why has it happened?), predictive (What is likely to happen next?) and prescriptive (What is the best option to follow?). Each type of analysis is based on a type of mathematical (statistics, numerical methods) or computer (machine learning, data mining, etc.) techniques. It is important to know the type of analysis and specific techniques that are useful for each situation, since that is what will determine the tools that we can use to do it. For example, to find out if there is more incidence of the virus in cities or in rural areas, a descriptive analysis can be carried out using traditional basic statistics. Instead, to know when the next wave of viruses is likely to occur, we can employ machine learning and/or data mining. Depending on the types of analysis that are carried out, data valorization initiatives can be distinguished between Data Science projects o Business Intelligence projects (BI, Business intelligence). The word 'business' in the latter refers to doing what is right for an organization to achieve its objectives. Table 1 summarizes the main differences between them. This separation often does not exist in reality because the projects combine various types of analysis, being both Data Science and Business Intelligence. It is also frequent that the needs and types of analysis are not completely known a priori or they change depending on the evolution of the project.
Machine learning, or machine learning (machine learning), is a group of techniques used to discover patterns in data and make predictions. Includes decision trees, linear regression, clustering (clustering) and neural networks, among others. Its name comes from the fact that some of them, in the case of neural networks, are based on imitating how the human brain learns. There are many software tools to facilitate its realization, such as TensorFlow, Cloud AutoML or Azure ML.
Name data mining evidence of similarity with traditional mining. Indeed, physical mining uses techniques to extract a small valuable portion by processing immense amounts of earth from the ground and the second extracts valuable information by processing large amounts of data. There are multiple technologies for data mining. Some are specialized tools, like RapidMiner. There are also programming languages like R and DAX. Others are general purpose, like the Python language. A special case is the process mining of business, very relevant for the digital transformation of organizations, since it analyzes data that reflects everything relevant that occurs in the internal processes of an organization (selling, storing, manufacturing, caring for patients, etc.) and, based on them, obtains information to change for the better (analysis prescriptive) the way to carry out the processes.
As a complement to data analysis, many projects include proper data visualization (top row in Figure 3). The Data visualization It can be very relevant to add value, facilitating the consultation and understanding of those responsible for making decisions. There are specialized software tools that make it possible to obtain systems in which the user interface is highly visual and interactive thanks to the use of predefined interaction patterns. This is the case of tools such as Tableau or Power BI (Figure 4 shows their use to create the example with COVID data). Some tools, like Power BI, include facilities for all stages of Data projects, from downloading data from sources to analysis of various kinds and visualization. They are known as ABI platforms (Analytics and Business Intelligence).
Once a Data project has been completed (concluded all the stages of Figure 2), you enter the Explotacion of your results. At this point, other knowledge and skills of Data professionals come into play. Data is a highly valuable and strategic asset and, therefore, it is relevant to implement practices to ensure that the organization has the data it needs, when, how and with the appropriate quality and security. The Data Governance establishes the strategy to meet these organizational needs (example: comply with the European regulation for the protection of personal data) and the Data management implement concrete practices to comply with them, for example, how to avoid isolated data silos in the different departments of the company. Other aspects that Data professionals should always keep in mind are: the Quality (accuracy, precision, etc.), the Security in all its dimensions of integrity, confidentiality and availability; and the Privacy when it comes to personal data. How do I ensure there is no duplicate data with different values? Who can access each data? o How do I eliminate or reduce risks of data loss? These are questions that need to be answered correctly by Data professionals.
We have presented the main computer skills and knowledge that may be required in a project focused on Data. They are very broad and it is difficult for the same person to gather all of them in sufficient depth. Therefore, it may be convenient to set professional profiles different. It is what the norm does "European ICT Professional Role Profiles"(https://itprofessionalism.org/about-it-professionalism/competences/ict-profiles/), which distinguishes between Data Scientist (Data Scientist), Data Specialist (Data Specialist) and Data Manager (Data Administrator). The first focuses, above all, on data analysis, the second on data modeling and governance aspects, and the third on data repository management and security.
One last aspect to highlight in the Data Science and Engineering profession is that projects can be multidisciplinary. In addition to profiles with the knowledge and skills presented in this article, in many projects it is necessary to have other non-computer profiles, especially application domain experts and mathematicians/statisticians.
The domain experts of application are the people who know very well the field of application of the data (for example, experts in public health and epidemics) and for this reason they are the ones who know well what is of interest to measure and with which indicators decisions must be made. Their role at the beginning of the project is key to the identification of needs and to know the existing data sources. On the other hand, these domain experts are the future users of the systems developed in the Data projects and, therefore, it is highly desirable that they participate in validating the results. The mathematical/statistical they can contribute with a deeper knowledge of some of the analysis techniques for the case of numerical quantitative data.
Data has its Science and its Engineering. The great importance they have requires professionals, in Data Science and Engineering, who know how to carry out projects that add value to organizations and society.
Francisco Ruiz (francisco.ruizg@uclm.es)
Mario Piattini (Mario.piattini@uclm.es)


