



Aprendizaje por refuerzo: área menos conocida del machine learning
Por Enrique Villarrubia (estudiante de Máster y Doctorado).
Habitualmente, el aprendizaje automático o machine learning es conocido por el aprendizaje supervisado y no supervisado. Ambos necesitan disponer de observaciones o datos para trabajar con el fin de explorar posibles patrones subyacentes. El primero de ellos, a partir de datos etiquetados aprende a predecir la salida (clasificación o regresión), y el segundo, aprende la estructura inherente de los datos y nos ayuda a entenderlos mejor. Pero, ¿y el aprendizaje por refuerzo?
El aprendizaje por refuerzo se basa en cómo un agente aprende interactuando en un entorno sin indicarle qué acciones debe realizar, sino que debe descubrir qué acciones conducen a la máxima recompensa al probarlas. La mejor similitud a un ejemplo real es cómo los niños aprenden a través de prueba y error. ¡Veámoslo con un ejemplo y cómo se relaciona con los elementos básicos del aprendizaje por refuerzo!
Supongamos que estamos jugando al videojuego de Super Mario Bros. El entorno es el videojuego en sí, la imagen que estamos viendo en el monitor es el estado actual, las posibles acciones corresponden con los botones de movimiento en las 4 direcciones y saltar, y, por último, las recompensas serán positivas cuando derrotemos a un Woompa o completemos el nivel y negativas cuando nos eliminen o conforme pase el tiempo, ya que queremos incentivar que el agente se mueva y aprenda explorando el entorno. En la siguiente imagen se presenta un resumen de estos elementos básicos en el aprendizaje por refuerzo.

En los últimos años, gracias al aprendizaje por refuerzo profundo (el empleo de redes neuronales para aproximar cualquier componente del aprendizaje por refuerzo) y a los árboles de búsqueda de Montecarlo, se ha conseguido vencer al campeón del mundo del juego de mesa Go, que es más complejo computacionalmente que el ajedrez, con el algoritmo AlphaGo [2]. Tal fue la repercusión que incluso Netflix produjo un documental al respecto con la compañía inglesa DeepMind que desarrolló el algoritmo [3]. Posteriormente, el algoritmo fue evolucionando para no requerir del uso de conocimiento experto de jugadores a través de la generación de partidas del agente contra sí mismo (AlphaGo Zero) [4], adaptado a más juegos como el ajedrez y el shogi (AlphaZero) [5] y, por último, a no necesitar conocer las reglas de los mismos (MuZero) [6]. Además, también podemos encontrarnos estos rendimientos sobrehumanos en videojuegos más complejos con información imperfecta como en StarCraft II (AlphaStar) [7]. Este algoritmo emplea aprendizaje supervisado en sus primeras iteraciones, pero es gracias al aprendizaje por refuerzo que consigue dar este salto de calidad para conseguir el nivel de habilidad de Gran Maestro (el mayor del juego) y ganar a los campeones del mundo.

Y ahora, muy posiblemente te estés preguntado, ¿y sólo sirve el aprendizaje por refuerzo para juegos? ¡No! Los juegos son empleados para tareas de benchmarking y comprobar lo buenos que son estos algoritmos, pero actualmente podemos encontrarnos con aplicaciones reales como controlar el plasma ardiente dentro de un reactor de fusión nuclear Tokamak [9], logrando un control mucho mejor que el que se tenía con los sistemas anteriores, o multitud de aplicaciones en robótica y otros campos del conocimiento.
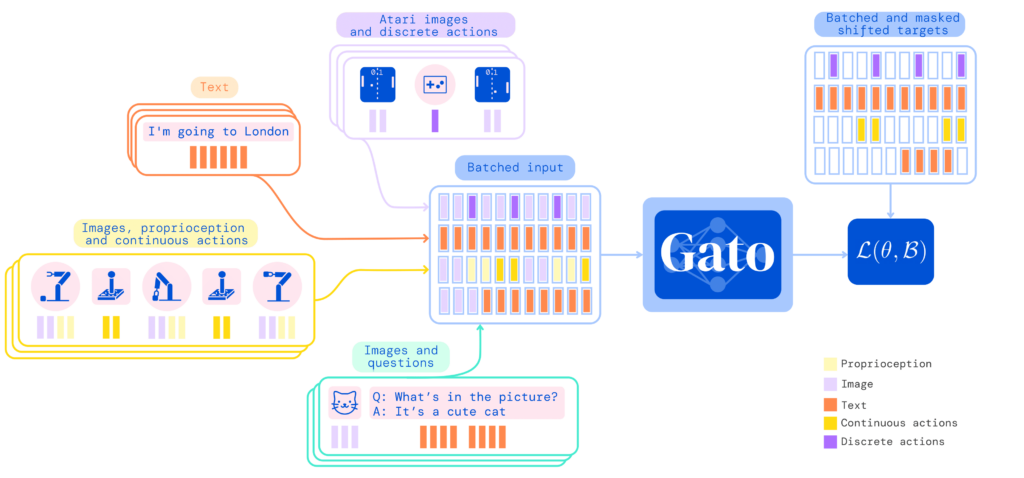
Finalmente, hoy en día, los últimos avances en el aprendizaje por refuerzo están centrados en resolver problemas seq2seq (secuencia a secuencia) con el empleo de mecanismos de atención y el entrenamiento paralelizable ofrecido por los transformers (un modelo de red neuronal). En la siguiente imagen se puede observar a Gato [10], una inteligencia artificial generalista diseñada con estos pretextos capaz de completar frases, jugar a los juegos de Atari, apilar cajas con un brazo mecánico, ser un chatbot, etc., todo con el mismo modelo y sin necesidad de volver a entrenarlo para cada una de las tareas.
Como conclusión, aunque el aprendizaje por refuerzo no sea tan famoso como sus otros dos hermanos del aprendizaje automático, hemos podido comprobar sus grandes hitos y la utilidad que presenta sobre todo en determinados entornos. Por último, gracias por leer este artículo y espero que te haya parecido interesante el tema, el cuál a mí me encanta.
Referencias.
[1] «An Introduction to Reinforcement Learning». FreeCodeCamp.Org, 31 de marzo de 2018, https://www.freecodecamp.org/news/an-introduction-to-reinforcement-learning-4339519de419/
[2] Silver, David, et al. «Mastering the Game of Go with Deep Neural Networks and Tree Search». Nature, vol. 529, n.o 7587, enero de 2016, pp. 484-89.https://doi.org/10.1038/nature16961
[3] «AlphaGo Movie». AlphaGo Movie, https://www.alphagomovie.com/
[4] Silver, David, et al. «Mastering the Game of Go without Human Knowledge». Nature, vol. 550, n.o 7676, octubre de 2017, pp. 354-59. https://doi.org/10.1038/nature24270
[5] Silver, David, et al. «A General Reinforcement Learning Algorithm That Masters Chess, Shogi, and Go through Self-Play». Science, vol. 362, n.o 6419, diciembre de 2018, pp. 1140-44.https://doi.org/10.1126/science.aar6404
[6] Schrittwieser, Julian, et al. «Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model». Nature, vol. 588, n.o 7839, diciembre de 2020, pp. 604-09. https://doi.org/10.1038/s41586-020-03051-4
[7] Vinyals, Oriol, et al. «Grandmaster Level in StarCraft II Using Multi-Agent Reinforcement Learning». Nature, vol. 575, n.o 7782, noviembre de 2019, pp. 350-54. https://doi.org/10.1038/s41586-019-1724-z
[8] AlphaStar: Mastering the Real-Time Strategy Game StarCraft II. https://www.deepmind.com/blog/alphastar-mastering-the-real-time-strategy-game-starcraft-ii
[9] Degrave, Jonas, et al. «Magnetic Control of Tokamak Plasmas through Deep Reinforcement Learning». Nature, vol. 602, n.o 7897, febrero de 2022, pp. 414-19. https://doi.org/10.1038/s41586-021-04301-9
[10] Reed, Scott, et al. «A Generalist Agent». arXiv:2205.06175 [cs], mayo de 2022. arXiv.org, http://arxiv.org/abs/2205.06175


