



Reinforcement Learning: Weniger bekannter Bereich des maschinellen Lernens
von Enrique Villarrubia (Master- und Doktorand).
Typischerweise maschinelles Lernen bzw Maschinelles Lernen ist bekannt für überwachtes und unüberwachtes Lernen. Beide benötigen Beobachtungen oder Daten, mit denen sie arbeiten können, um mögliche zugrunde liegende Muster zu untersuchen. Der erste von ihnen lernt anhand von gekennzeichneten Daten, die Ausgabe vorherzusagen (Klassifizierung oder Regression), und der zweite lernt die inhärente Struktur der Daten und hilft uns, sie besser zu verstehen. Aber was ist mit bestärkendem Lernen?
Reinforcement Learning basiert darauf, wie ein Agent lernt, indem er in einer Umgebung interagiert, ohne dass ihm gesagt wird, welche Aktionen er ausführen soll, sondern indem er herausfindet, welche Aktionen zur maximalen Belohnung führen, indem er sie ausprobiert. Die beste Ähnlichkeit mit einem realen Beispiel besteht darin, wie Kinder durch Versuch und Irrtum lernen. Sehen wir es uns anhand eines Beispiels an und wie es sich auf die Grundlagen des bestärkenden Lernens bezieht!
Angenommen, wir spielen das Videospiel Super Mario Bros. Die Umgebung ist das Videospiel selbst, das Bild, das wir auf dem Monitor sehen, ist der aktuelle Zustand, die möglichen Aktionen entsprechen den 4-Wege-Bewegungs- und Sprungtasten und schließlich , die Belohnungen sind positiv, wenn wir einen Woompa besiegen oder das Level abschließen, und negativ, wenn wir eliminiert werden oder wenn die Zeit vergeht, da wir den Agenten ermutigen möchten, sich zu bewegen und durch Erkunden der Umgebung zu lernen. Das folgende Bild zeigt eine Zusammenfassung dieser grundlegenden Elemente des bestärkenden Lernens.

In den letzten Jahren war es dank Deep Reinforcement Learning (der Verwendung neuronaler Netze zur Annäherung an jede Komponente des Reinforcement Learning) und Monte-Carlo-Suchbäumen möglich, den Weltmeister des Brettspiels Go zu schlagen, das rechenintensiver ist als Schach, mit dem AlphaGo-Algorithmus [2]. Die Wirkung war so groß, dass sogar Netflix mit der englischen Firma DeepMind, die den Algorithmus entwickelt hat, eine Dokumentation darüber produzierte [3]. Anschließend wurde der Algorithmus weiterentwickelt, um den Einsatz von Expertenwissen von Spielern durch die Generierung von Spielen des Agenten gegen sich selbst (AlphaGo Zero) [4] nicht zu erfordern, angepasst an mehr Spiele wie Schach und Shogi (AlphaZero) [ 5] und schließlich ihre Regeln nicht kennen zu müssen (MuZero) [6]. Darüber hinaus finden wir diese übermenschlichen Leistungen auch in komplexeren Videospielen mit unvollständigen Informationen wie in StarCraft II (AlphaStar) [7]. Dieser Algorithmus verwendet in seinen ersten Iterationen überwachtes Lernen, aber dank Reinforcement Learning schafft er diesen Qualitätssprung, um die Fertigkeitsstufe Großmeister (die höchste im Spiel) zu erreichen und die Weltmeister zu schlagen.

Und jetzt fragen Sie sich wahrscheinlich, ob Reinforcement Learning nur für Spiele nützlich ist? Nö! Spiele werden für Aufgaben von verwendet Benchmarking und überprüfen Sie, wie gut diese Algorithmen sind, aber derzeit können wir echte Anwendungen finden, wie die Steuerung des brennenden Plasmas in einem Tokamak-Kernfusionsreaktor [9], das Erreichen einer viel besseren Steuerung als bei früheren Systemen, oder viele Anwendungen in der Robotik und anderen Bereichen des Wissens.
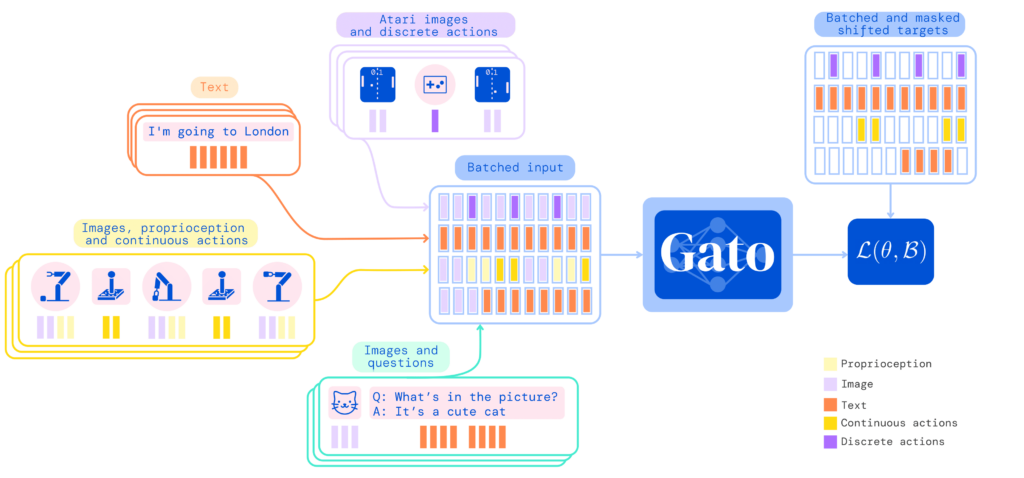
Schließlich konzentrieren sich die neuesten Fortschritte im Reinforcement Learning heute auf die Lösung von seq2seq-Problemen (Sequenz für Sequenz) unter Verwendung von Aufmerksamkeitsmechanismen und dem parallelisierbaren Training, das von angeboten wird Transformer (ein neuronales Netzwerkmodell). Im folgenden Bild sehen Sie Gato [10], eine generalistische künstliche Intelligenz, die mit diesen Vorwänden entwickelt wurde und in der Lage ist, Sätze zu vervollständigen, Atari-Spiele zu spielen, Kisten mit einem mechanischen Arm zu stapeln, ein Chatbot zu sein usw., alles mit demselben Modell und ohne die Notwendigkeit, es für jede der Aufgaben neu zu trainieren.
Zusammenfassend lässt sich sagen, dass Reinforcement Learning zwar nicht so berühmt ist wie seine beiden anderen Brüder des maschinellen Lernens, aber wir konnten seine großen Meilensteine und die Nützlichkeit, die es bietet, insbesondere in bestimmten Umgebungen, verifizieren. Abschließend danke, dass Sie diesen Artikel gelesen haben, und ich hoffe, Sie fanden das Thema interessant, das ich liebe.
Verweise.
[1] «Eine Einführung in das Reinforcement Learning». FreeCodeCamp.Org, 31. März 2018, https://www.freecodecamp.org/news/an-introduction-to-reinforcement-learning-4339519de419/ [2] Silber, David, et al. «Das Game of Go mit tiefen neuronalen Netzen und Baumsuche meistern». Naturvol. 529, n.o 7587, Januar 2016, p. 484-89.https://doi.org/10.1038/nature16961 [3] "AlphaGo-Film". Alpha Go-Film, https://www.alphagomovie.com/ [4] Silber, David, et al. «Das Go-Spiel ohne menschliches Wissen meistern». Naturvol. 550, n.o 7676, Oktober 2017, p. 354-59. https://doi.org/10.1038/nature24270 [5] Silber, David, et al. "Ein allgemeiner Verstärkungslernalgorithmus, der Schach, Shogi und Selbstspiel beherrscht". Wissenschaftvol. 362, n.o 6419, Dezember 2018, p. 1140-44.https://doi.org/10.1126/science.aar6404 [6] Schrittwieser, Julian, et al. "Beherrschung von Atari, Go, Schach und Shogi durch Planung mit einem erlernten Modell". Naturvol. 588, n.o 7839, Dezember 2020, p. 604-09. https://doi.org/10.1038/s41586-020-03051-4 [7] Vinyals, Oriol, et al. "Grandmaster Level in StarCraft II mit Multi-Agent Reinforcement Learning". Naturvol. 575, n.o 7782, November 2019, p. 350-54. https://doi.org/10.1038/s41586-019-1724-z [8] AlphaStar: Meistere das StarCraft-Echtzeit-Strategiespiel II. https://www.deepmind.com/blog/alphastar-mastering-the-real-time-strategy-game-starcraft-ii [9] Degrave, Jonas, et al. «Magnetische Kontrolle von Tokamak-Plasmen durch Deep Reinforcement Learning». Naturvol. 602, n.o 7897, Februar 2022, p. 414-19. https://doi.org/10.1038/s41586-021-04301-9 [10] Reed, Scott, et al. «Ein Generalist-Agent». arXiv:2205.06175 [cs], Mai 2022. arXiv.org, http://arxiv.org/abs/2205.06175

