



強化學習:機器學習中鮮為人知的領域
通過 恩里克·維拉魯比亞 (碩士和博士生)。
通常,機器學習或 機器學習 以有監督和無監督學習而聞名。 兩者都需要有觀察結果或數據來探索可能的潛在模式。 第一個從標記數據中學習預測輸出(分類或回歸),第二個學習數據的固有結構並幫助我們更好地理解它。 但是強化學習呢?
強化學習基於智能體如何通過在環境中進行交互來學習,而不被告知要執行什麼動作,而是通過嘗試發現哪些動作會帶來最大的回報。 與真實例子最相似的地方是孩子們如何通過反複試驗來學習。 讓我們通過一個例子來看看它與強化學習的基礎知識之間的關係!
假設我們正在玩超級馬里奧兄弟遊戲,環境就是遊戲本身,我們在顯示器上看到的圖像是當前狀態,可能的動作對應於 4 向移動和跳躍按鈕,最後, ,當我們擊敗 Woompa 或完成關卡時,獎勵將是積極的,而當我們被淘汰或隨著時間的推移,獎勵將是消極的,因為我們希望通過探索環境來鼓勵智能體移動和學習。 下圖總結了強化學習中的這些基本元素。

近年來,由於深度強化學習(使用神經網絡來逼近強化學習的任何組成部分)和蒙特卡洛搜索樹,已經有可能擊敗圍棋的世界冠軍,圍棋的計算複雜度比圍棋高國際象棋,使用 AlphaGo 算法 [2]。 這就是影響,甚至 Netflix 也與開發該算法的英國公司 DeepMind 一起製作了一部關於它的紀錄片 [3]。 隨後,算法演變為不需要使用玩家的專家知識,通過生成代理對抗自身的遊戲(AlphaGo Zero)[4],適應更多遊戲,如國際象棋和將棋(AlphaZero)[5]最後,不需要知道他們的規則(MuZero)[6]。 此外,我們還可以在諸如星際爭霸 II (AlphaStar) [7] 等信息不完整的更複雜視頻遊戲中找到這些超人表現。 該算法在其第一次迭代中使用了監督學習,但正是由於強化學習,它設法在質量上實現了這一飛躍,從而達到了大師級技能水平(遊戲中的最高水平)並擊敗了世界冠軍。

現在,您很可能想知道,強化學習是否只對遊戲有用? 沒有! 遊戲用於以下任務 標杆 並檢查這些算法有多好,但目前我們可以找到真正的應用,例如控制託卡馬克核聚變反應堆 [9] 內的燃燒等離子體,實現比以前系統更好的控制,或者在機器人技術和其他領域的許多應用的知識。
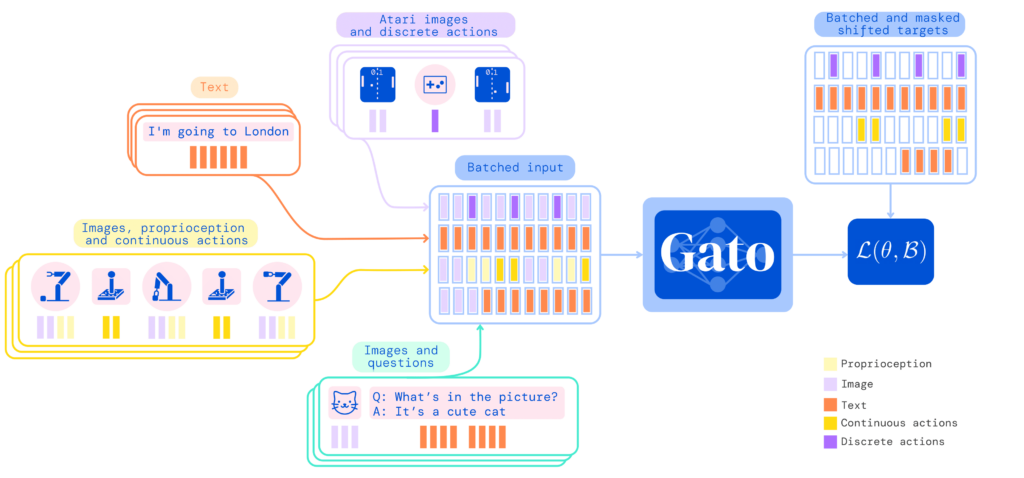
最後,今天,強化學習的最新進展集中在使用注意力機制和由 變壓器 (神經網絡模型)。 在下圖中,您可以看到 Gato [10],這是一種使用這些藉口設計的通用人工智能,能夠完成句子、玩 Atari 遊戲、用機械臂堆疊盒子、成為聊天機器人等,所有這些都具有相同的模型並且沒有需要為每個任務重新訓練它。
總之,儘管強化學習不像其他兩個機器學習兄弟那樣有名,但我們已經能夠驗證它的偉大里程碑和它所呈現的有用性,尤其是在某些環境中。 最後,感謝您閱讀本文,我希望您發現這個話題很有趣,我很喜歡。
參考。
[1] «強化學習簡介»。 FreeCodeCamp.org, 31 年 2018 月 XNUMX 日, https://www.freecodecamp.org/news/an-introduction-to-reinforcement-learning-4339519de419/ [2] 西爾弗、大衛等人。 «用深度神經網絡和樹搜索掌握圍棋遊戲»。 性質,卷529號o 7587,2016 年 484 月,p。 89-XNUMX。https://doi.org/10.1038/nature16961 [3] “阿爾法圍棋電影”。 阿爾法圍棋電影, https://www.alphagomovie.com/ [4] 西爾弗、大衛等人。 «在沒有人類知識的情況下掌握圍棋遊戲»。 性質,卷550號o 7676,2017 年 354 月,第59-XNUMX。 https://doi.org/10.1038/nature24270 [5] 西爾弗、大衛等人。 “掌握國際象棋、將棋和自我對弈的通用強化學習算法”。 科學,卷362號o 6419,2018 年 1140 月,第44-XNUMX。https://doi.org/10.1126/science.aar6404 [6] Schrittwieser,朱利安等人。 “通過學習模型進行規劃,掌握雅達利、圍棋、國際象棋和將棋”。 性質,卷588號o 7839,2020 年 604 月,第09-XNUMX。 https://doi.org/10.1038/s41586-020-03051-4 [7] Vinyals、Oriol 等人。 《星際爭霸 II 中的宗師級使用多智能體強化學習》。 性質,卷575號o 7782,2019 年 350 月,第54-XNUMX。 https://doi.org/10.1038/s41586-019-1724-z [8] AlphaStar:掌握星際爭霸即時戰略遊戲II. https://www.deepmind.com/blog/alphastar-mastering-the-real-time-strategy-game-starcraft-ii [9] 德格雷夫、喬納斯等人。 «通過深度強化學習對託卡馬克等離子體進行磁控制»。 性質,卷602號o 7897,2022 年 414 月,p。 19-XNUMX。 https://doi.org/10.1038/s41586-021-04301-9 [10] 里德、斯科特等人。 «通才代理»。 arXiv:2205.06175 [CS], 2022 年 XNUMX 月。 arXiv.org, http://arxiv.org/abs/2205.06175

