



Explication de l'algorithme
Par Francisco Pascal Romero (Coordinateur du Master U. en Ingénierie Informatique)
Cette semaine, on apprend qu'il y a eu, malheureusement, 26 morts sur les routes espagnoles. Cela améliore les prévisions du Big Data, ou plutôt des algorithmes d'intelligence artificielle qui utilisent le Big Data, qui étaient au nombre de 36.
Plusieurs questions découlent de cette prédiction, tout d'abord, un chiffre absolu n'est normalement pas prédit ou prévu, les résultats d'une prédiction sont généralement un peu plus complexes, par exemple, un degré de confiance du chiffre est offert ou dans quel intervalle il est plus fiable ce chiffre. Un seul chiffre est une bonne donnée pour le public mais pas vraiment utile.
D'autre part, à de nombreuses reprises, le processus de calcul du nombre est plus précieux que le nombre lui-même. Vraisemblablement, des variables telles que les séries chronologiques, les circonstances météorologiques, etc. ont été prises en compte pour obtenir ce "36". Connaître les facteurs qui influencent la prédiction est l'un des éléments les plus précieux qui existent pour aider à la prise de décision.
Enfin, il y a la distorsion de la prédiction elle-même. Lorsque vous prédisez quelque chose à propos d'un phénomène, vous l'affectez déjà. C'est quelque chose que j'ai appris du professeur José Angel Olivas il y a plus de 20 ans et il est toujours valable. Par exemple, la DGT utilise le chiffre pour conditionner notre comportement à travers une campagne publicitaire, en essayant de nous inciter à être plus prudents au volant. C'est-à-dire que le "big data" est utilisé pour que le "big data" ne fasse pas les choses correctement, car l'important n'est pas de faire les choses correctement mais de réduire le nombre de décès sur la route.
Autre exemple : Nadal à l'Open d'Australie.
Tout le monde a vu l'image des 4% de chances de victoire de Nadal face à Medveveed en finale du dernier Open d'Australie. Les gros titres suivants ressemblaient à "Nadal Beats Big Data", etc. Quelques semaines plus tard, Marco Asensio marque un but qui, selon le modèle diffusé à la télévision, avait 10% de chances d'être un but. Par la suite, titres identiques, ce qui nous arrive peut-être, c'est que lorsque nous pointons la lune, nous regardons du doigt et nous ne réalisons pas ce qui se cache derrière ces chiffres.
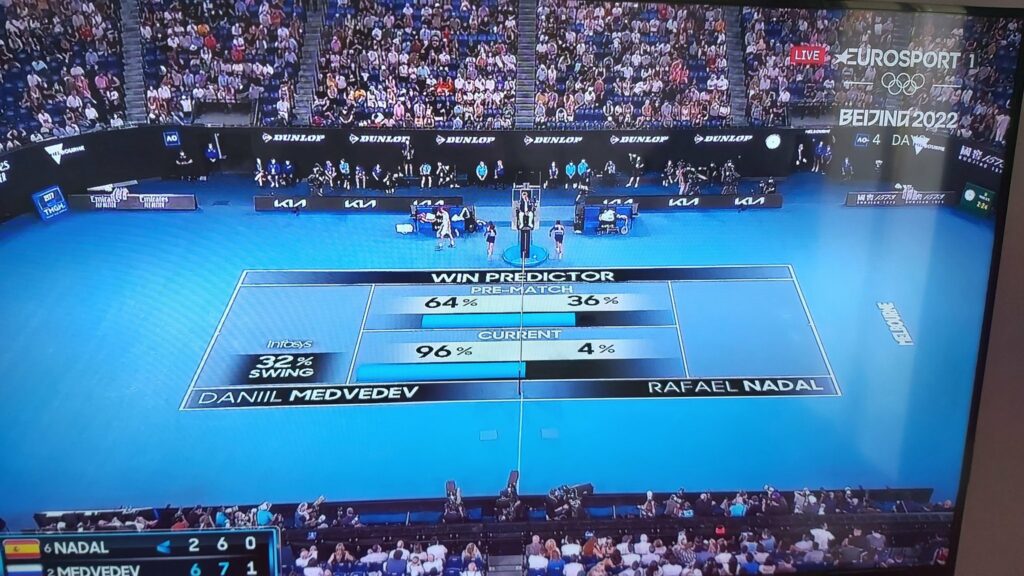
Probabilité vs Possibilité. Une probabilité de 4% indique que la victoire de Nadal était possible et plus encore avec le système de notation du tennis. Ce n'est pas un événement impossible, c'est rare, mais ce n'est pas impossible. Arrêtons-nous un instant, chaque 21 décembre nous pensons que le lendemain nous gagnerons le gros lot de la loterie, et cela avec une probabilité de 0,001%, et nous considérons toujours cela comme possible.
Comment le modèle calcule-t-il ce nombre ? En premier lieu, une probabilité a priori est utilisée dans laquelle Nadal avait une probabilité de 36% de gagner le match. Normalement, ces modèles a priori sont basés sur les classements (supérieurs à ceux de Medveded), les séries passées, la surface de jeu, les derniers matchs, etc. Ensuite, il y a l'avenir du parti ; En prenant un modèle simple qui analyse des situations historiques similaires, seuls 4 matchs sur 100 à 5 sets ont eu un résultat comme celui qui a été retracé. Si nous nous concentrons sur Nadal, il n'était venu que de 2 matchs sur 20 dans cette situation. Le nombre est donc justifié, mais nous donne-t-il suffisamment d'informations ?
Comment arrive-t-on à ce chiffre ? Un nombre est un instant, et en valorisant un instant on perd une partie de l'histoire. Rappelons-nous le principe d'incertitude de Heisenberg : si nous évaluons très précisément une variable, nous perdons de vue le reste. D'un autre côté, atteindre ces 4% à partir de 1% n'est pas la même chose qu'avoir chuté de 32%. Et non seulement cela, il est non seulement nécessaire d'évaluer ce nombre, mais aussi comment il a évolué plus tard pendant le match, et comment différents événements tels que sauver une balle de break ou avoir un break au-dessus dans le troisième set peuvent grandement changer cette probabilité de la victoire. Ces événements, les connaître et les analyser sont la clé de cette analyse.
Comment puis-je changer cette probabilité? C'est la partie utile du nombre, si vous dites à un moment donné à un joueur qu'il a 4% de chance de victoire vous ne lui donnez rien de nouveau, il le sait en regardant le tableau d'affichage. La chose importante à contribuer est ce qui se passe dans votre jeu qui vous mène à la défaite et comment vous pouvez changer cette dynamique. C'est-à-dire que l'utile serait de dire : "regarde Rafa, il gagne tous les points que tu lances avec le deuxième service, et tu n'as pas de double faute, garde ça à l'esprit" ou "des services qui il te lance dans l'autre sens tu perds 90% et avec des échanges de moins de 3 balles ». C'est quelque chose qui peut être utile au joueur et à l'entraîneur, c'est la véritable utilité de l'application de ces algorithmes et modèles.
En conclusion, les chiffres isolés sont ces chiffres, mais ils ont besoin d'un contexte et d'une analyse détaillée, il n'y a pas besoin d'une interprétation « numérique » de ceux-ci. Les algorithmes et les modèles peuvent fournir beaucoup plus d'informations et de connaissances pertinentes qui vous permettent de comprendre les comportements et comment obtenir de meilleurs résultats.


