



Takviyeli öğrenme: daha az bilinen makine öğrenimi alanı
tarafından Enrique Villarrubia (Yüksek lisans ve doktora öğrencisi).
Tipik olarak, makine öğrenimi veya makine öğrenme denetimli ve denetimsiz öğrenme için bilinir. Her ikisinin de olası altta yatan kalıpları keşfetmek için birlikte çalışacak gözlemlere veya verilere sahip olması gerekir. Bunlardan ilki, etiketlenmiş verilerden çıktıyı (sınıflandırma veya regresyon) tahmin etmeyi öğrenir ve ikincisi, verilerin doğal yapısını öğrenir ve onu daha iyi anlamamıza yardımcı olur. Peki ya pekiştirmeli öğrenme?
Takviyeli öğrenme, bir aracının hangi eylemleri gerçekleştireceği söylenmeden bir ortamda etkileşim kurarak nasıl öğrendiğine dayanır, bunun yerine hangi eylemlerin onları deneyerek maksimum ödüle yol açtığını keşfeder. Gerçek bir örneğe en iyi benzerlik, çocukların deneme yanılma yoluyla nasıl öğrendikleridir. Bunu bir örnekle ve pekiştirmeli öğrenmenin temelleriyle nasıl bir ilişkisi olduğunu görelim!
Diyelim ki Super Mario Bros video oyunu oynuyoruz, ortam video oyununun kendisi, monitörde gördüğümüz görüntü mevcut durum, olası eylemler 4 yönlü hareket ve atlama düğmelerine karşılık geliyor ve, Son olarak , bir Woompa'yı yendiğimizde veya seviyeyi tamamladığımızda ödüller olumlu, elendiğimizde veya zaman geçtikçe olumsuz olacaktır, çünkü aracıyı çevreyi keşfederek hareket etmeye ve öğrenmeye teşvik etmek istiyoruz. Aşağıdaki görüntü, pekiştirmeli öğrenmedeki bu temel unsurların bir özetini sunmaktadır.

Son yıllarda, derin pekiştirmeli öğrenme (pekiştirmeli öğrenmenin herhangi bir bileşenine yaklaşmak için sinir ağlarının kullanılması) ve Monte Carlo arama ağaçları sayesinde, hesaplama açısından daha karmaşık olan masa oyunu Go'nun dünya şampiyonunu yenmek mümkün olmuştur. AlphaGo algoritması [2] ile satranç. Öyle bir etki yaptı ki Netflix bile algoritmayı geliştiren İngiliz şirketi DeepMind ile bu konuda bir belgesel hazırladı [3]. Daha sonra, algoritma, ajanın kendisine karşı oyunlarının oluşturulması yoluyla oyuncuların uzman bilgisinin kullanılmasını gerektirmeyecek şekilde gelişti (AlphaGo Zero) [4], satranç ve shogi gibi daha fazla oyuna uyarlandı (AlphaZero) [ 5] ve son olarak, kurallarını bilmeye gerek duymama (MuZero) [6]. Ayrıca, bu insanüstü performansları, StarCraft II (AlphaStar) [7] gibi kusurlu bilgilere sahip daha karmaşık video oyunlarında da bulabiliriz. Bu algoritma, ilk yinelemelerinde denetimli öğrenmeyi kullanır, ancak takviyeli öğrenme sayesinde, Grandmaster beceri seviyesine (oyundaki en yüksek seviye) ulaşmak ve dünya şampiyonlarını yenmek için kalitede bu sıçramayı başarır.

Ve şimdi, büyük olasılıkla merak ediyorsunuz ve pekiştirmeli öğrenme sadece oyunlar için mi faydalı? Hayır! Oyunlar görevleri için kullanılır kıyaslama ve bu algoritmaların ne kadar iyi olduğunu kontrol edin, ancak şu anda bir Tokamak nükleer füzyon reaktörü [9] içindeki yanan plazmayı kontrol etmek, önceki sistemlerden çok daha iyi kontrol elde etmek veya robotik ve diğer alanlarda çok sayıda uygulama gibi gerçek uygulamalar bulabiliriz. bilginin.
Son olarak, bugün, pekiştirmeli öğrenmedeki en son gelişmeler, dikkat mekanizmalarının kullanımı ve paralelleştirilebilir eğitim ile seq2seq (sırayla dizi) problemlerini çözmeye odaklanmıştır. transformatörler (bir sinir ağı modeli). Aşağıdaki görselde, bu bahanelerle tasarlanmış, cümle tamamlama, Atari oyunları oynama, mekanik kollu kutuları istifleme, chatbot olma vb. görevlerin her biri için yeniden eğitme ihtiyacı.
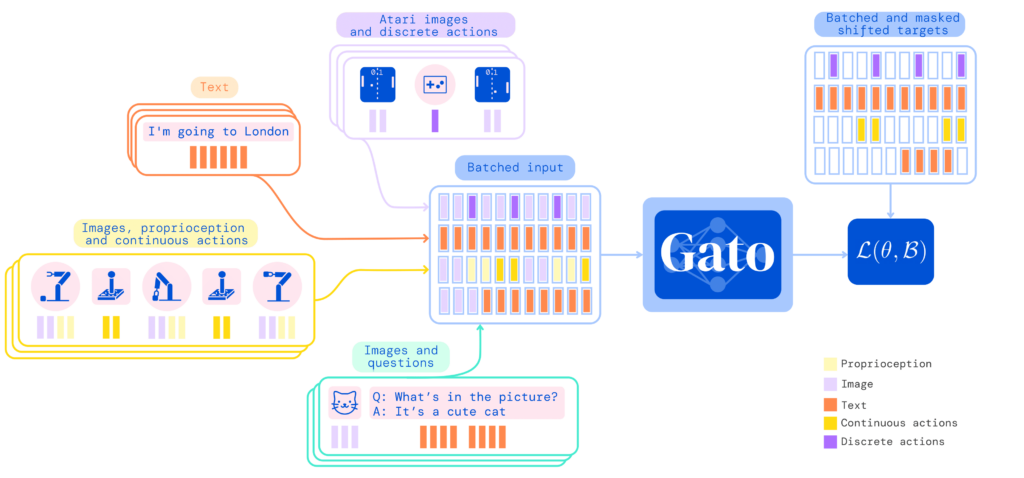
Sonuç olarak, pekiştirmeli öğrenme, diğer iki makine öğrenimi kardeşi kadar ünlü olmasa da, büyük kilometre taşlarını ve özellikle belirli ortamlarda sunduğu kullanışlılığı doğrulayabildik. Son olarak, bu makaleyi okuduğunuz için teşekkür ederim ve umarım sevdiğim konuyu ilginç bulmuşsunuzdur.
Referanslar.
[1] «Takviyeli Öğrenmeye Giriş». FreeCodeCamp.Org, 31 Mart 2018, https://www.freecodecamp.org/news/an-introduction-to-reinforcement-learning-4339519de419/ [2] Silver, David, et al. "Derin Sinir Ağları ve Ağaç Arama ile Go Oyununda Ustalaşmak". Tabiat, cilt. 529, n.o 7587, Ocak 2016, s. 484-89.https://doi.org/10.1038/nature16961 [3] "AlphaGo Filmi". Alfa Git Filmi, https://www.alphagomovie.com/ [4] Silver, David, et al. "İnsan Bilgisi Olmadan Go Oyununda Ustalaşmak". Tabiat, cilt. 550, n.o 7676, Ekim 2017, s. 354-59. https://doi.org/10.1038/nature24270 [5] Silver, David, et al. "Satrançta, Shogi'de Ustalaşan ve Kendi Kendine Oynama Yoluyla Devam Eden Genel Takviyeli Öğrenme Algoritması". Bilim, cilt. 362, n.o 6419, Aralık 2018, s. 1140-44.https://doi.org/10.1126/science.aar6404 [6] Schrittwieser, Julian, et al. "Öğrenilmiş Bir Modelle Planlayarak Atari, Go, Satranç ve Shogi'de Ustalaşmak". Tabiat, cilt. 588, n.o 7839, Aralık 2020, s. 604-09. https://doi.org/10.1038/s41586-020-03051-4 [7] Viniller, Oriol, et al. "Çok Aracılı Takviye Öğrenimi Kullanarak StarCraft II'de Büyük Usta Seviyesi". Tabiat, cilt. 575, n.o 7782, Kasım 2019, s. 350-54. https://doi.org/10.1038/s41586-019-1724-z [8] AlphaStar: StarCraft Gerçek Zamanlı Strateji Oyununda Ustalaşmak II. https://www.deepmind.com/blog/alphastar-mastering-the-real-time-strategy-game-starcraft-ii [9] Degrave, Jonas, et al. "Derin Takviyeli Öğrenme Yoluyla Tokamak Plazmalarının Manyetik Kontrolü". Tabiat, cilt. 602, n.o 7897, Şubat 2022, s. 414-19. https://doi.org/10.1038/s41586-021-04301-9 [10] Reed, Scott, et al. "Bir Genelci Ajan". arXiv:2205.06175 [cs], Mayıs 2022. arXiv.org, http://arxiv.org/abs/2205.06175

