



數據、科學、工程和專業
通過 弗朗西斯科·魯伊斯 y 馬里奧·皮亞蒂尼 (大學教授)。
他們說只有打雷時我們才會記得聖巴巴拉。 這在西班牙很明顯,就像在幾乎所有國家一樣,在 COVID 大流行開始時,政府無法獲得足夠的數據來了解情況並做出更明智的決定。 幾個月後,當局才開始擁有以適當的形式和時間向他們提供數據的系統。 然而它的可信度和準確性還沒有被廣泛接受。
數據、信息和知識 它們經常被用作同義詞,但事實並非如此。 數據是原始價值,原材料。 當它們被置於上下文中時,它們被稱為信息。 最後,知識是某種形式和背景下對特定目的有用的信息。 例如,“195”是原始數據,“Luis is 195 cm”是信息,“Luis is a tall person because he is 195 cm”是知識。
數據可用於從中產生新知識和/或做出更好的決策,從而能夠優化成本,為公民提供更好的服務,更好地滿足我們用戶或客戶的利益和需求,或“改善內部以便在外部引起注意”(流程改進)。 近年來,由於信息技術的發展,這種相關性已經發展到數據被認為是個人、組織或國家的一種新的財富來源。 它的收集和分析是實現新發現和有益變化的關鍵,例如更有效地抗擊流行病,了解每個城市和地區的空氣質量以採取適當的措施或實時了解交通狀況以便能夠採取措施快速防止或減少交通擁堵。 可能性是無窮無盡的,但其中也有可能帶來負面後果的可能性。 為此,數據從業者必須具備強烈的責任感和職業道德。
數據有其科學與工程,但對數據的定義尚未達成共識 數據科學 因此,無論是在其限制與 數據工程.
為了澄清這一點,我們引用著名的匈牙利裔美國物理學家和工程師西奧多·馮·卡門 (Theodore von Kármán) 的話:“l科學家研究世界的本來面目,而工程師則創造前所未有的世界。 換句話說,科學的目標是了解現實,而工程學的目標是通過創造新的技術產品來改變現實。 應用到物理世界,我們可以推斷出研究宇宙黑洞是科學,而設計和建造望遠鏡來研究它們是工程。 類似地,應用於數據,我們可以得出數據科學尋求從數據中獲取新知識,而數據工程尋求使用數據改變現實。 可以在“數據管理知識體系”中找到更詳盡和有限的定義(數據管理知識體系), 由 DAMA (https://www.dama.org),國際數據管理專業人員協會。 DAMA 將數據科學與試圖預測未來聯繫起來,將其定義為“構建探索數據中包含的模式的預測模型”。 為此,它“將數據挖掘、統計分析和機器學習與數據集成和建模能力相結合”,並“遵循科學方法,通過提出和驗證假設、觀察結果以及製定解釋結果的一般理論來提高知識”。
在現實生活中,數據科學和工程的目標往往是密不可分的,因為為了從數據中獲取新知識(科學),首先需要設計和創建能夠正確存儲和處理它們的技術系統(工程)。
同一個人有時從事數據科學和其他數據工程的情況甚至很常見。 出於這個原因,更方便地說數據科學與工程”,包括兩者,因為該學科專注於借助信息技術 (IT) 從數據中獲取價值。
為了利用數據,有必要 多樣化的知識和技能. 了解它們是什麼的主要國際參考是 ACM 提案(計算機機械協會,計算領域最負盛名的國際協會),被譽為“本科數據科學課程的計算能力“(可在 https://www.acm.org/education/curricula-recommendations). 它確定了以下 XNUMX 個知識和能力領域(我們保留了英文的原始首字母縮略詞):數據分析和呈現 (AP); 人工智能(AI); 大數據系統(BDS); 計算機和信息學基礎 (CCF); 數據採集、管理和治理(DG); 數據挖掘(DM); 數據安全 (DP) 的隱私、安全、完整性和分析; 機器學習(機器學習); 專業精神(公關); 編程、數據結構和算法(PDA); 軟件開發和維護 (SDM)。 其中一些對於計算和 IT 中的其他學科是常見的。 其他人則特別關注數據科學與工程專業人士的職責,例如數據分析和呈現; 大數據系統; 數據採集、管理和治理; 和數據挖掘。
另一個相關來源是前面提到的 DAMA 協會,它提供了一種專注於數據管理(數據工程的一部分)的方法。 您已確定的相關知識和能力被分組到圖 1 中所示的區域中。
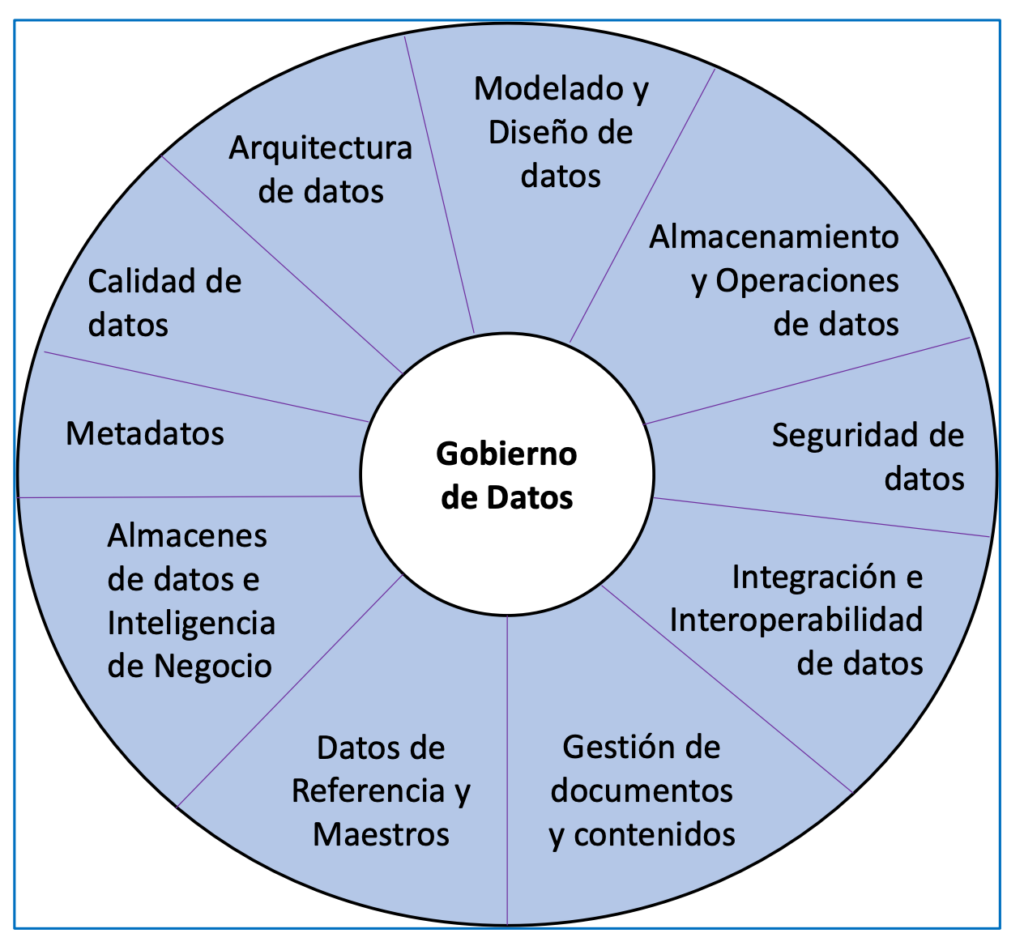
CEPIS(歐洲專業信息學協會理事會)認為,優秀的專業人士是將知識、技能、培訓、責任和道德相結合的人,能夠為他人增加價值。
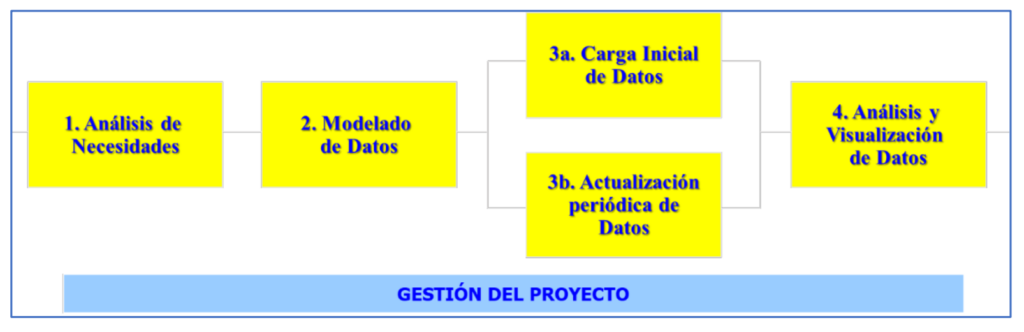
以上兩個技能和知識的集合是劃界的一個很好的起點。 數據科學與工程專業,其目的是從數據中提取價值。 因此,該學科專業人士的價值必須通過他們從數據中為其他人和組織或整個社會獲取價值的能力來衡量。 為了實現這一價值,數據專業人員開展的工作和項目的最終結果通常是創建信息系統,使數據可視化和分析,並能夠從中提取新知識。 這些項目通常按圖 2 所示的階段進行。
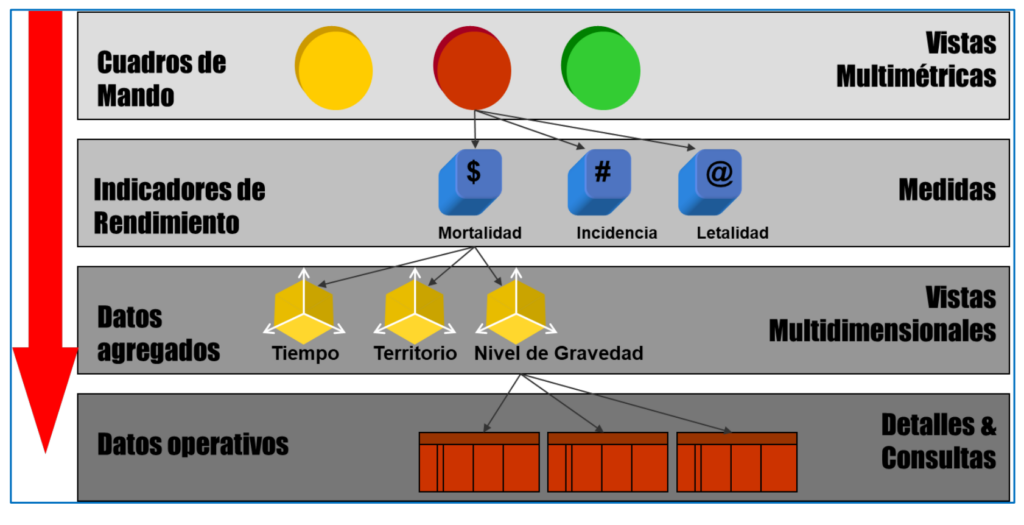
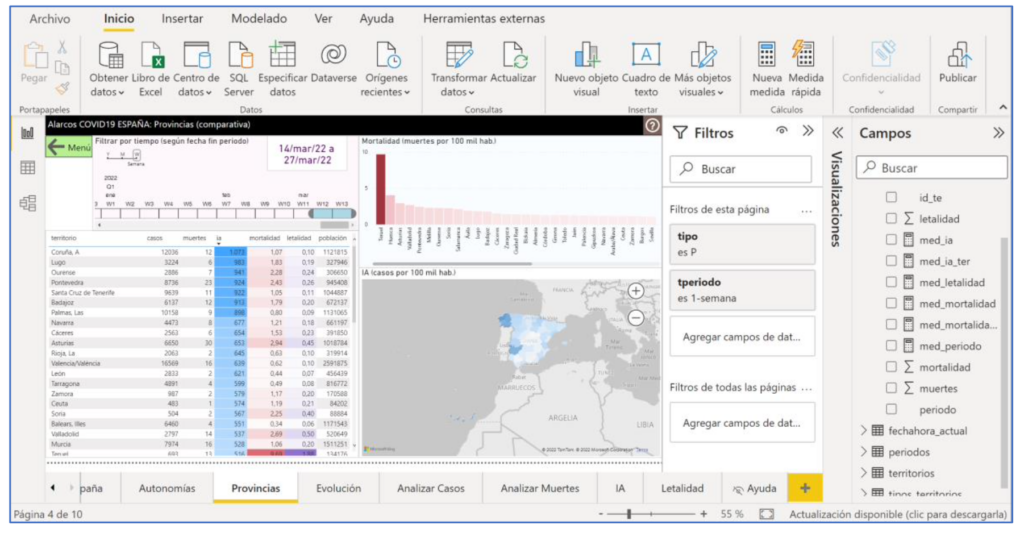
在項目的各個階段,專家在四個不同級別處理數據和信息,如圖 3 所示,並以 COVID 大流行數據為例。 它從原始運營數據(每個地區每天的病例數和死亡人數)開始。 接下來,您需要確定分析數據的維度,例如,按時間(發生的時間)、地域(發生的地點)和嚴重程度(發生的情況)。 這需要處理數據(通常使用實現特定算法的軟件工具)以將它們分組到每個分析維度的適當詳細級別。 例如,時間上按天、週、月,地域上按地、省、自治區等。 從這些匯總的數據中,我們可以按照需要的方式,計算出相關的決策指標,例如每個省份每週的累計發病率(每100萬居民的病例數)。 最後,指標值和其他數據通常通過信息系統(“儀表板”和其他類型)提供給非計算機,便於數據的可視化和分析以供決策使用。 在 https://alarcos.esi.uclm.es/covid19esp/ 顯示了一個帶有真實 COVID 數據的示例。
下面介紹了數據增值項目階段的一些相關方面(圖 2)。
首先,你要了解需求。 在數據項目中,這側重於識別 衡量什麼以及如何衡量 適當地,並從中找到 來源 我們在哪裡可以獲得必要的數據。
在第二階段,處理數據的一個關鍵方面得到解決:給它一個適當的結構和形式,以便能夠將它存儲在計算機上,並能夠用它做我們想做的一切。 該任務與數據項目的成功相關,就像“制定正確的建築計劃”與建築項目的相關性一樣。 在這個問題上,架構的通用概念(在 ISO 42010 標準中定義)很有用。 就這樣 '數據架構' 建立我們將它們分開的元素或隔間(表、文件等)以及所述元素之間的關係。 還需要很好地定義每個隔間的內部結構(它存儲什麼具體數據)以及每個具體數據的類型或性質(數字、日期、文本、音頻、視頻、文檔……)。 這 數據建模 它包括使用適合項目需求的體系結構和數據結構來“創建藍圖”。 這些藍圖可以用實體-關係、關係或多維模式的形式表示。
從原始數據到準備分析的數據可能是一項相當複雜的任務。 它類似於水的情況,為了使其適合人類飲用,必須從它產生的源頭進行各種轉變,並且還必須為此建造不同類型的管道和管道。 因此,有必要從結構清晰的現有計算機文件(CSV、Excel 等)中識別原始數據的所有來源。.) 到非結構化格式的數據,例如網絡或社交網絡。 這 ETL 流程,用於提取、轉換和加載,包括:i) 從原始來源下載原始數據; ii) 將它們轉化為適當和同質的格式和結構; iii)將它們集成到存儲庫中或 數據倉庫,基於之前建立的數據架構。 要進行 ETL,您可以使用傳統技術(例如 SQL),但使用專門為此設計的其他技術(Power Query、Big Query 等)可以提高工作效率。 近年來的替代方法是使用 數據湖 (數據湖). 它是一種避免創建集成數據存儲並用異構數據集合代替它的技術,這些數據保留其原始格式,但存儲在同一計算機系統中。 為了保證通用和集成訪問,有必要 元數據 (關於數據的數據)。
與數據建模密切相關的數據科學與工程專業人員的需求是知道如何處理 技術 計算 存儲和處理數據 有效率的和有效地。
沒有它,就不可能開展第三階段的數據增值項目(圖 2)。 上述數據存儲庫可以使用兩種技術來完成:數據管理系統 數據庫 (傳統關係型,如 ORACLE、MySQL 等;或非關係型,如 MongoDB)和工具 大數據 (Hadoop、Elasticsearch 等)。 當需要處理大量數據時,後者會取代前者,從而解決被稱為大數據 7 V 的數據管理挑戰:數據量、速度、多樣性、準確性、可行性、可視化和價值。 另一種通常與大數據搭配使用的選擇是上述數據湖技術。
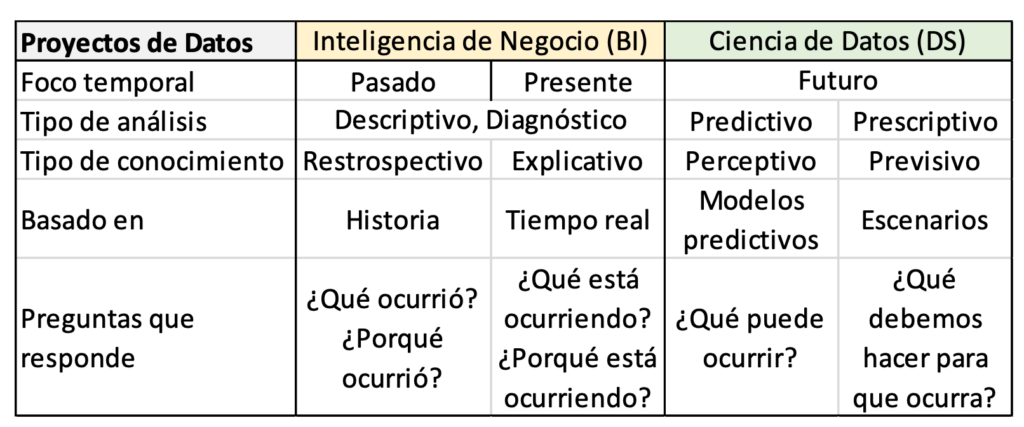
創建並填充存儲庫或其等效物後,第四階段是通過分析和可視化真正從數據中提取價值。 要做到這一點,首先要知道的類型 數據分析 可以這樣做,具體取決於您要回答的問題類型: 描述性的 (發生了什麼?), 診斷 (為什麼會這樣?), 預測性的 (接下來可能會發生什麼?)和 規定的 (最好的選擇是什麼?)。 每種類型的分析都基於一種數學(統計、數值方法)或計算機(機器學習、數據挖掘等)技術。 了解對每種情況有用的分析類型和特定技術很重要,因為這將決定我們可以用來執行此操作的工具。 例如,要了解該病毒的發病率是在城市還是在農村,可以使用傳統的基礎統計數據進行描述性分析。 相反,要知道下一波病毒何時可能發生,我們可以採用機器學習和/或數據挖掘。 根據所執行的分析類型,數據增值計劃可以區分為 數據科學項目 o 商業智能項目 (雙, 商業智能). 後者中的“業務”一詞是指為組織實現其目標而做正確的事情。 表 1 總結了它們之間的主要區別。 這種分離在現實中通常不存在,因為項目結合了各種類型的分析,包括數據科學和商業智能。 分析的需求和類型並不完全先驗地知道,或者它們根據項目的演變而變化也很常見。
機器學習, 或機器學習 (機器學習), 是一組用於發現數據模式並進行預測的技術。 包括決策樹、線性回歸、聚類(集群) 和神經網絡等。 它的名字來源於這樣一個事實,即在神經網絡的情況下,其中一些是基於模仿人腦的學習方式。 有許多軟件工具可以促進其實現,例如 TensorFlow、Cloud AutoML 或 Azure ML。
這個名字 數據挖掘 與傳統採礦相似的證據。 事實上,物理採礦使用技術通過處理來自地面的大量地球來提取一小部分有價值的部分,而第二種方法通過處理大量數據來提取有價值的信息。 有多種數據挖掘技術。 有些是專用工具,例如 RapidMiner。 還有像 R 和 DAX 這樣的編程語言。 其他的是通用的,比如 Python 語言。 一個特例是 過程挖掘 的業務,非常相關的 數字化轉型 組織的,因為它分析的數據反映了組織內部流程(銷售、存儲、製造、患者護理等)中發生的所有相關內容,並基於這些數據獲取信息以做出更好的改變(分析規範) 執行流程的方式。
作為對數據分析的補充,許多項目都包括適當的數據可視化(圖 3 中的頂行)。 這 數據可視化 它可以增加價值,促進負責決策的人員的協商和理解。 由於使用預定義的交互模式,有專門的軟件工具可以獲得用戶界面高度可視化和交互的系統。 Tableau 或 Power BI 等工具就是這種情況(圖 4 顯示了它們使用 COVID 數據創建示例的情況)。 一些工具,如 Power BI,包括適用於數據項目所有階段的工具,從從源下載數據到各種類型的分析和可視化。 它們被稱為 ABI 平台(分析和商業智能).
數據項目完成後(結束圖 2 的所有階段),您進入 開發 你的結果。 此時,數據專業人員的其他知識和技能開始發揮作用。 數據是一種非常有價值的戰略資產,因此,它與實施實踐相關,以確保組織擁有所需的數據,以及何時、如何以及以適當的質量和安全性。 這 數據治理 制定戰略以滿足這些組織需求(例如:遵守歐洲個人數據保護法規)和 數據管理 實施具體實踐以遵守它們,例如,如何避免公司不同部門中孤立的數據孤島。 數據專業人員應始終牢記的其他方面是: 質量 (準確度、精密度等), 安全 在完整性、機密性和可用性的所有方面; 和 隱私 當涉及到個人數據時。 如何確保沒有具有不同值的重複數據? 誰可以訪問每個數據? o 如何消除或降低數據丟失的風險? 這些是數據專業人員需要正確回答的問題。
我們介紹了專注於數據的項目可能需要的主要計算機技能和知識。 它們非常廣泛,同一個人很難將所有這些都收集到足夠的深度。 因此,可以方便地設置 專業檔案 不同的。 這就是規範所做的“歐洲 ICT 專業角色簡介“(https://itprofessionalism.org/about-it-professionalism/competences/ict-profiles/), 它區分數據科學家 (數據科學家), 數據專家 (數據專家) 和數據管理器 (資料管理員). 首先,第一個側重於數據分析,第二個側重於數據建模和治理方面,第三個側重於數據存儲庫管理和安全性。
數據科學與工程專業要強調的最後一個方面是 項目 可以 多學科. 除了具有本文介紹的知識和技能的個人資料外,在許多項目中還需要其他 非計算機配置文件,尤其是應用領域專家和數學家/統計學家。
很多 領域專家 應用的人是非常了解數據應用領域的人(例如,公共衛生和流行病方面的專家),因此他們是那些非常了解要衡量的利益以及決策必須使用哪些指標的人製作。 他們在項目開始時的作用是確定需求和了解現有數據源的關鍵。 另一方面,這些領域專家是數據項目中開發的系統的未來用戶,因此,非常希望他們參與驗證結果。 這 數學/統計 他們可以對數值定量數據的一些分析技術有更深入的了解。
數據有其科學和工程。 他們的重要性需要數據科學與工程領域的專業人員,他們知道如何開展為組織和社會增加價值的項目。
弗朗西斯科·魯伊斯 (francisco.ruizg@uclm.es)
馬里奧·皮亞蒂尼 (Mario.piattini@uclm.es)


