



Dati, scienza, ingegneria e professione
da Francisco Ruiz y Mario Piattini (professori universitari).
Dicono che ricordiamo Santa Barbara solo quando tuona. Ciò era evidente in Spagna, come in quasi tutti i paesi, quando, all'inizio della pandemia di COVID, i governi non potevano disporre di dati adeguati per comprendere la situazione e prendere decisioni più informate. Dovettero passare diversi mesi prima che le autorità iniziassero a disporre di sistemi che fornissero loro i dati, nella forma e nei tempi adeguati. Eppure la sua credibilità e accuratezza non sono state ampiamente accettate.
Dati, informazioni e conoscenza Sono spesso usati come sinonimi, ma non lo sono. I dati sono i valori grezzi, la materia prima. Quando sono inquadrati in un contesto si chiamano informazioni. Infine, la conoscenza è informazione in una forma e in un contesto utili per determinati scopi. Ad esempio, "195" sono dati grezzi, "Luis è 195 cm" è informazioni e "Luis è una persona alta perché è 195 cm" è conoscenza.
I Dati possono essere utili per, da loro, generare nuove conoscenze e/o prendere decisioni migliori, e quindi essere in grado di ottimizzare i costi, offrire servizi migliori ai cittadini, servire meglio gli interessi e le esigenze dei nostri utenti o clienti, o "migliorare dentro in modo che sia notato all'esterno” (miglioramento del processo). Negli ultimi anni, grazie allo sviluppo delle tecnologie informatiche, questa rilevanza è cresciuta al punto che i dati sono considerati una sorta di nuova fonte di ricchezza, per individui, organizzazioni o paesi. La sua raccolta e analisi è fondamentale per ottenere nuove scoperte e cambiamenti benefici, come combattere una pandemia in modo più efficace, conoscere la qualità dell'aria in ogni città e area per prendere le misure appropriate o conoscere la situazione del traffico in tempo reale per poter adottare misure per prevenire o ridurre rapidamente gli ingorghi. Le possibilità sono infinite, ma tra queste ci sono anche quelle con conseguenze potenzialmente negative. Per questo motivo, i professionisti dei dati devono essere intrisi di un forte senso di responsabilità ed etica professionale.
I dati hanno la loro scienza e ingegneria, ma non c'è consenso sulla definizione di Scienza dei dati e, quindi, né nei suoi limiti con l' Ingegneria dei dati.
Per chiarirlo prendiamo le parole di Theodore von Kármán, prestigioso fisico e ingegnere ungherese-americano: “lgli scienziati studiano il mondo così com'è mentre gli ingegneri creano il mondo che non è mai esistito prima. In altre parole, l'obiettivo della Scienza è conoscere la realtà, mentre quello dell'ingegneria è cambiarla creando nuovi artefatti tecnologici. Applicato al mondo fisico, possiamo dedurre che studiare i buchi neri dell'universo è Scienza, mentre progettare e costruire il telescopio per studiarli è Ingegneria. Allo stesso modo, applicato ai dati, possiamo dedurre che la scienza dei dati cerca di ottenere nuove conoscenze dai dati mentre l'ingegneria dei dati cerca di cambiare la realtà usando i dati. Una definizione più elaborata e limitata può essere trovata nel "Body of Knowledge on Data Management" (Organismo di conoscenza della gestione dei dati), prodotto da DAMA (https://www.dama.org), l'associazione internazionale dei professionisti della gestione dei dati. DAMA associa Data Science al tentativo di prevedere il futuro, definendolo come “la costruzione di modelli predittivi che esplorano modelli contenuti nei dati”. E per questo "combina data mining, analisi statistica e machine learning con capacità di integrazione e modellazione dei dati" e "segue il metodo scientifico per migliorare la conoscenza formulando e verificando ipotesi, osservando risultati e formulando teorie generali che spiegano i risultati".
Nella vita reale, gli obiettivi di Data Science e Engineering sono spesso inscindibili poiché, per ottenere nuova conoscenza dai dati (Science), è prima necessario progettare e realizzare sistemi tecnologici che li memorizzino ed elaborino correttamente (Engineering).
È anche frequente che la stessa persona a volte si occupi di scienza dei dati e altra ingegneria dei dati. Per questo è più conveniente parlarneScienza dei dati e ingegneria”, comprendendo entrambi, in quanto disciplina focalizzata sull'ottenimento di valore dai Dati grazie all'Information Technology (IT).
Per sfruttare i dati, è necessario conoscenze e competenze diverse. Il principale riferimento internazionale per sapere cosa sono è la proposta ACM (Associazione per le macchine informatiche, la più prestigiosa associazione internazionale nel campo dell'informatica), nota come "Competenze informatiche per il curriculum universitario in scienze dei dati” (disponibile en https://www.acm.org/education/curricula-recommendations). Individua le seguenti undici aree di conoscenza e competenza (lasciamo in inglese le sigle originali): Analisi e presentazione dei dati (AP); Intelligenza Artificiale (AI); Sistemi di Big Data (BDS); Fondamenti di informatica e informatica (CCF); Acquisizione, gestione e governance dei dati (DG); Estrazione di dati (DM); Privacy, sicurezza, integrità e analisi per la sicurezza dei dati (DP); Apprendimento automatico (ML); Professionalità (PR); Programmazione, strutture dati e algoritmi (PDA); e sviluppo e manutenzione del software (SDM). Alcuni di essi sono comuni ad altre discipline all'interno dell'informatica e dell'IT. Altri sono particolarmente focalizzati sulle responsabilità dei professionisti in Data Science e Engineering, come è il caso di Analisi e presentazione dei dati; Sistemi di Big Data; Acquisizione, gestione e governance dei dati; e estrazione di dati.
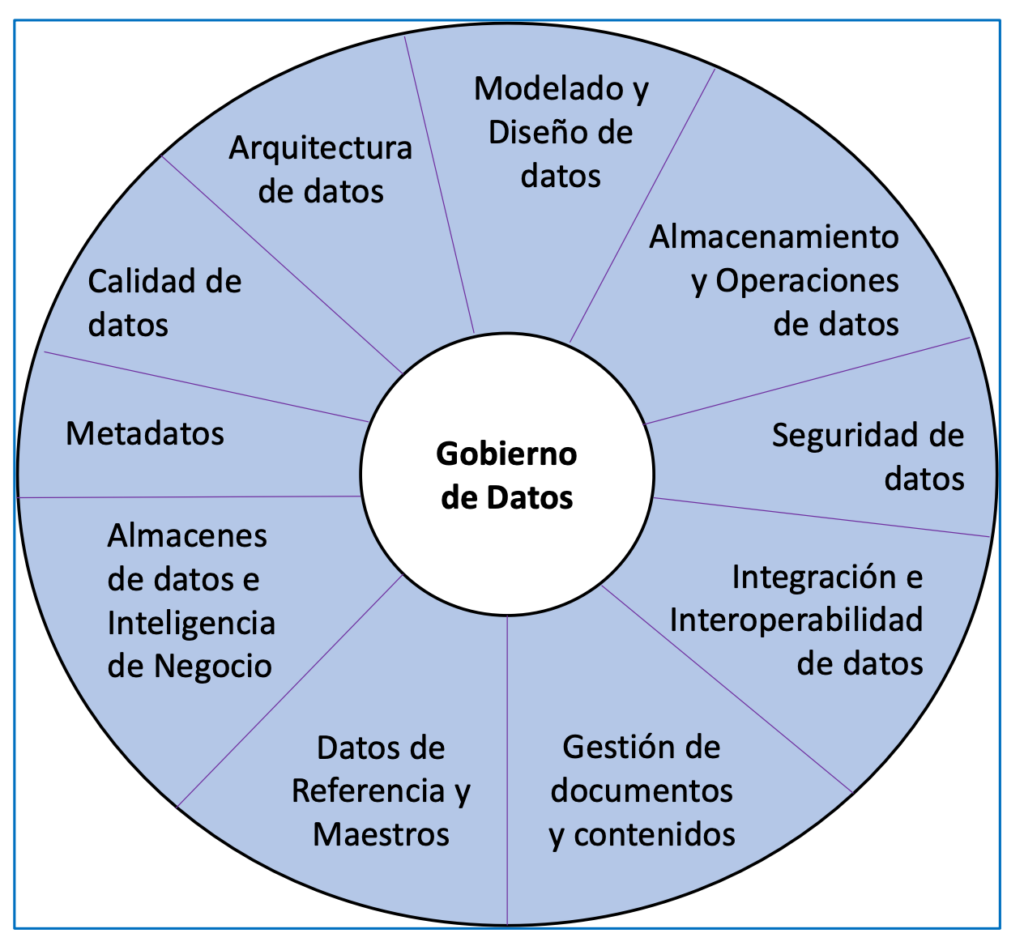
Un'altra fonte rilevante è la già citata associazione DAMA, che fornisce un approccio focalizzato sulla gestione dei dati (parte di Data Engineering). Le conoscenze e le competenze rilevanti che hai identificato sono raggruppate nelle aree mostrate nella Figura 1.
Il CEPIS (Council of European Professional Informatics Societies) stabilisce che un buon professionista è una persona che unisce conoscenze, abilità, formazione, responsabilità ed etica per essere in grado di aggiungere valore ad altre persone.
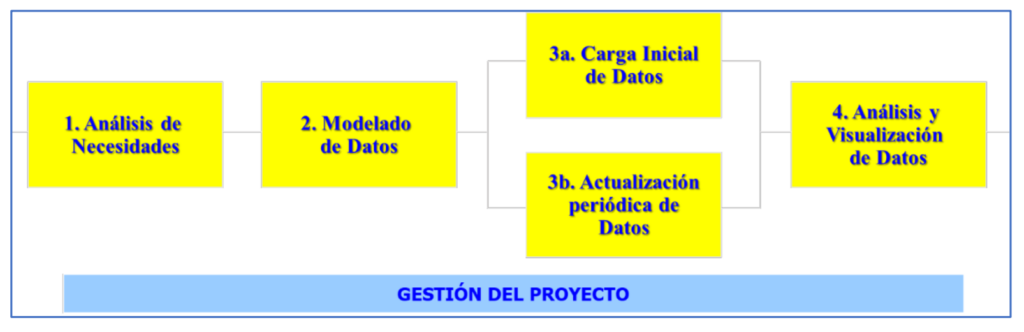
Le due precedenti raccolte di abilità e conoscenze sono un buon punto di partenza per delimitare il Professione di Data Science e Ingegneria, il cui scopo è quello di estrarre valore dai dati. Pertanto, il valore di un professionista in questa disciplina deve essere misurato dalla sua capacità di ottenere valore dai dati per altre persone e organizzazioni o per la società in generale. Per raggiungere tale valore, i professionisti dei dati realizzano sforzi e progetti il cui risultato finale è solitamente la creazione di sistemi informativi che consentono la visualizzazione e l'analisi dei dati e la possibilità di estrarne nuove conoscenze. Questi progetti vengono solitamente realizzati nelle fasi mostrate nella Figura 2.
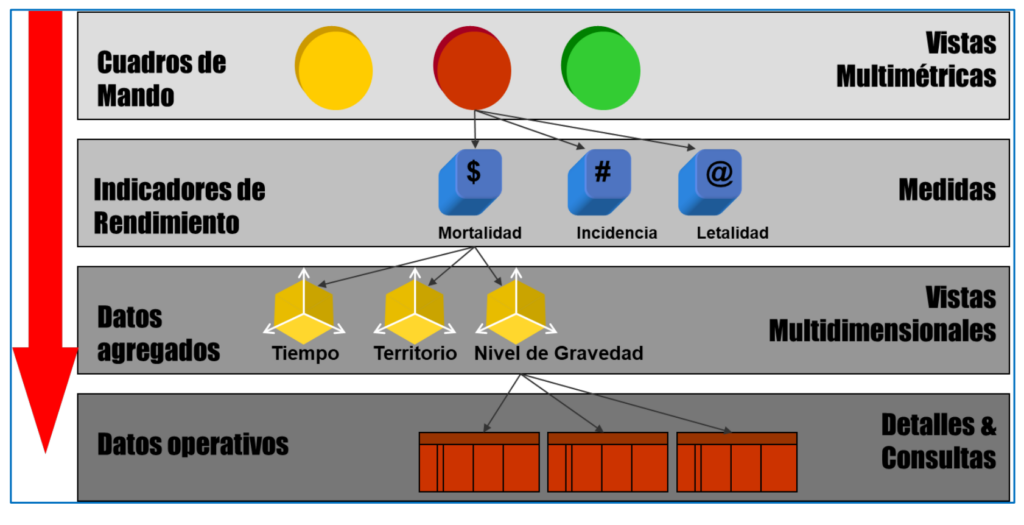
Durante le varie fasi di un progetto, gli esperti gestiscono dati e informazioni a quattro diversi livelli, mostrati nella Figura 3 con un esempio sui dati della pandemia COVID. Si parte dai dati operativi grezzi (numero di casi e decessi ogni giorno in ogni località). Successivamente, è necessario identificare le dimensioni per analizzare i dati, ad esempio in base all'ora (quando accade), al territorio (dove accade) e al livello di gravità (cosa accade). Ciò richiede l'elaborazione dei dati (di solito utilizzando strumenti software che implementano determinati algoritmi) per raggrupparli ai livelli di dettaglio appropriati per ogni dimensione di analisi. Ad esempio, nel caso del tempo, per giorni, settimane e mesi, o per località, province e comunità autonome nel caso della localizzazione territoriale. Da questi dati aggregati nel modo che serve, si può procedere a calcolare gli indicatori rilevanti per il processo decisionale, ad esempio l'incidenza cumulativa ogni settimana in ogni provincia (numero di casi per 100 abitanti). Infine, i valori degli indicatori e altri dati vengono solitamente forniti ai non informatici attraverso sistemi informativi ("cruscotti" e altri tipi) che facilitano la visualizzazione e l'analisi dei dati per il processo decisionale. In https://alarcos.esi.uclm.es/covid19esp/ Viene mostrato un esempio con dati COVID reali.
Di seguito sono presentati alcuni aspetti rilevanti delle fasi dei progetti di valorizzazione dei dati (Figura 2).
Prima di tutto, devi conoscere le esigenze. In un progetto Data questo si concentra sull'identificazione cosa misurare e come misurarlo in modo appropriato e, da questo, trovare il fonti dove possiamo ottenere i dati necessari per questo.
Nella seconda fase, viene affrontato un aspetto chiave per lavorare con i dati: dargli una struttura e una forma adeguate per poterli archiviare sui computer e poterne fare tutto ciò che vogliamo. Questo compito può essere rilevante per il successo di un progetto Data quanto "ottenere i piani di costruzione corretti" lo è per un progetto di costruzione. A questo proposito è utile la nozione generica di architettura (definita nella norma ISO 42010). Così, il 'architettura dei dati' Stabilisce gli elementi o compartimenti in cui li separiamo (tabelle, file, ecc.) e le relazioni tra detti elementi. È inoltre necessario definire bene la struttura interna di ciascun compartimento (quali dati specifici memorizza) e il tipo o la natura (numero, data, testo, audio, video, documento,...) di ciascun dato specifico. Il modellazione dei dati consiste nel 'creare i blueprint' con un'architettura e una struttura dati adatta alle esigenze del progetto. Questi schemi possono essere espressi sotto forma di schemi entità-relazione, relazionali o multidimensionali.
Passare dai dati grezzi ai dati preparati per l'analisi può essere un compito piuttosto complesso. È simile a quanto accade con l'acqua, che per essere idonea al consumo umano deve subire varie trasformazioni dalla sorgente da cui nasce, e per la quale devono essere costruiti anche diversi tipi di tubi e tubazioni. Pertanto, è necessario identificare tutte le fonti dei dati originali, da file informatici già disponibili con una struttura chiara (CSV, Excel, ecc..) a dati in formati non strutturati come il web o i social network. Il Processi ETL, per estrarre, trasformare e caricare, consiste in: i) scaricare i dati grezzi dalle fonti originali; ii) trasformarli in formati e strutture adeguati e omogenei; e iii) integrarli in un repository o magazzino dati, basato sull'architettura dei dati precedentemente stabilita. Per fare ETL puoi utilizzare le tecnologie tradizionali (come SQL), ma puoi essere più produttivo utilizzandone altre appositamente progettate per questo (Power Query, Big Query, ecc.). Un'alternativa negli ultimi anni è usare a lago di dati (lago di dati). Si tratta di una tecnologia che evita di creare un archivio dati integrato e lo sostituisce con una raccolta di dati eterogenei, che conserva il formato originale, ma viene archiviata nello stesso sistema informatico. Per garantire un accesso comune e integrato è necessario metadati (dati sui dati).
Un'esigenza del professionista di Data Science and Engineering, fortemente legata alla modellazione dei dati, è saper gestire il tecnologia informatica per archiviare ed elaborare i Dati efficientemente ed efficacemente.
Senza di esso, è impossibile realizzare la terza fase dei progetti di valorizzazione dei dati (Figura 2). Il suddetto archivio di dati può essere realizzato con due tipi di tecnologie: i sistemi di gestione dei dati database (tradizionali relazionali come ORACLE, MySQL, ecc.; o non relazionali come MongoDB) e strumenti per Big Data (Hadoop, Elasticsearch, ecc.). Questi ultimi sostituiscono i primi quando è necessario lavorare con enormi quantità di dati, consentendo di affrontare le sfide di gestione dei dati conosciute come le 7 V dei Big Data: volume, velocità, varietà, veridicità, fattibilità, visualizzazione e valore dei dati. Un'altra opzione, spesso abbinata ai Big Data, sono le già citate tecnologie di data lake.
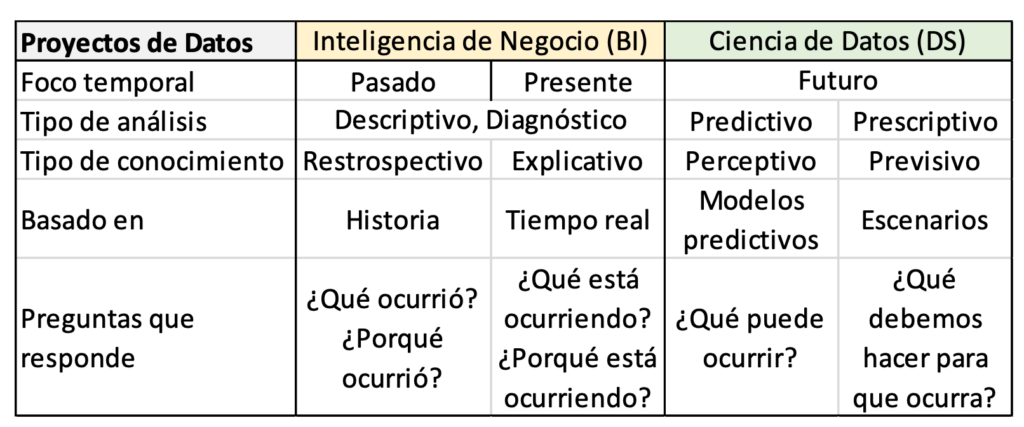
Una volta che il repository o il suo equivalente è stato creato e popolato, la quarta fase è quando il valore viene effettivamente estratto dai dati attraverso la sua analisi e visualizzazione. Per fare questo, la prima cosa è conoscere i tipi di Analisi dei dati che può essere fatto, a seconda del tipo di domande a cui vuoi rispondere: descrittivo (cosa è successo?), diagnosi (Perché è successo?), predittivo (Cosa è probabile che accada dopo?) e prescrittivo (Qual è l'opzione migliore da seguire?). Ogni tipo di analisi si basa su un tipo di tecniche matematiche (statistiche, metodi numerici) o informatiche (machine learning, data mining, ecc.). È importante conoscere il tipo di analisi e le tecniche specifiche utili per ogni situazione, poiché è ciò che determinerà gli strumenti che possiamo utilizzare per farlo. Ad esempio, per scoprire se c'è una maggiore incidenza del virus nelle città o nelle aree rurali, è possibile eseguire un'analisi descrittiva utilizzando le tradizionali statistiche di base. Invece, per sapere quando è probabile che si verifichi la prossima ondata di virus, possiamo utilizzare l'apprendimento automatico e/o il data mining. A seconda delle tipologie di analisi che vengono effettuate, si possono distinguere iniziative di valorizzazione dei dati Progetti di scienza dei dati o Progetti di Business Intelligence (BI, Business Intelligence). La parola "business" in quest'ultimo si riferisce a fare ciò che è giusto affinché un'organizzazione raggiunga i propri obiettivi. La tabella 1 riassume le principali differenze tra loro. Questa separazione spesso non esiste nella realtà perché i progetti combinano vari tipi di analisi, essendo sia Data Science che Business Intelligence. È inoltre frequente che le esigenze e le tipologie di analisi non siano completamente note a priori o cambino a seconda dell'evoluzione del progetto.
Apprendimento automaticoo apprendimento automatico (machine learning), è un gruppo di tecniche utilizzate per scoprire schemi nei dati e fare previsioni. Include alberi decisionali, regressione lineare, clustering (il clustering) e reti neurali, tra gli altri. Il suo nome deriva dal fatto che alcuni di essi, nel caso delle reti neurali, si basano sull'imitazione del modo in cui il cervello umano apprende. Esistono molti strumenti software per facilitarne la realizzazione, come TensorFlow, Cloud AutoML o Azure ML.
Nome estrazione dei dati prove di somiglianza con l'estrazione mineraria tradizionale. Infatti, l'estrazione fisica utilizza tecniche per estrarre una piccola porzione preziosa elaborando immense quantità di terra dal terreno e la seconda estrae informazioni preziose elaborando grandi quantità di dati. Esistono diverse tecnologie per il data mining. Alcuni sono strumenti specializzati, come RapidMiner. Esistono anche linguaggi di programmazione come R e DAX. Altri sono di uso generale, come il linguaggio Python. Un caso particolare è il estrazione di processo di business, molto rilevante per il trasformazione digitale delle organizzazioni, poiché analizza i dati che riflettono tutto ciò che è rilevante che si verifica nei processi interni di un'organizzazione (vendita, conservazione, produzione, assistenza ai pazienti, ecc.) e, sulla base di essi, ottiene informazioni per cambiare in meglio (analisi prescrittiva ) il modo di svolgere i processi.
Come complemento all'analisi dei dati, molti progetti includono una corretta visualizzazione dei dati (riga superiore nella Figura 3). Il Visualizzazione dati Può essere molto importante per aggiungere valore, facilitando la consultazione e la comprensione dei responsabili delle decisioni. Esistono strumenti software specializzati che consentono di ottenere sistemi in cui l'interfaccia utente è altamente visiva e interattiva grazie all'utilizzo di schemi di interazione predefiniti. Questo è il caso di strumenti come Tableau o Power BI (la Figura 4 mostra il loro utilizzo per creare l'esempio con i dati COVID). Alcuni strumenti, come Power BI, includono funzionalità per tutte le fasi dei progetti di dati, dal download dei dati dalle fonti all'analisi di vario tipo e alla visualizzazione. Sono conosciute come piattaforme ABI (Analisi e Business Intelligence).
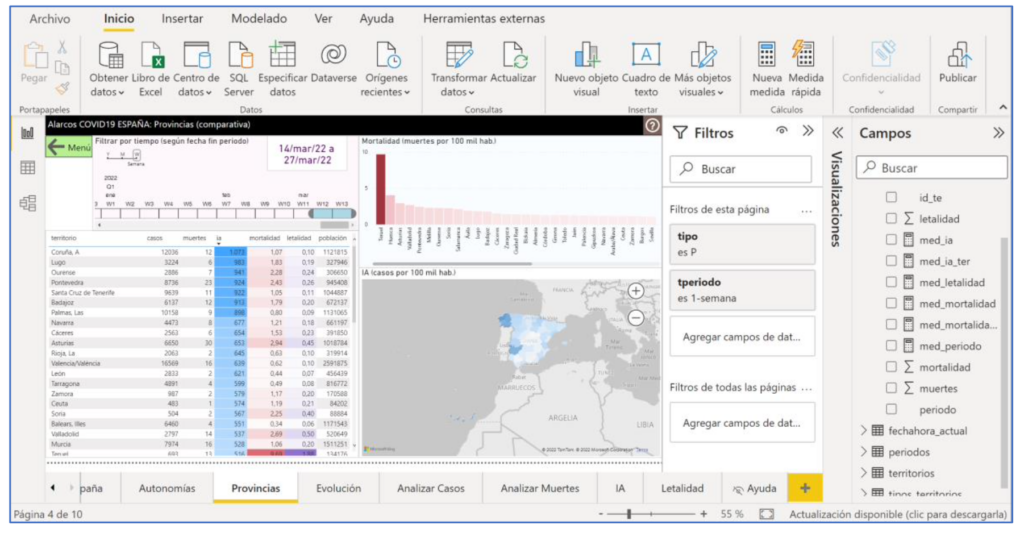
Una volta completato un progetto Dati (concluse tutte le fasi di Figura 2), si entra nel file sfruttamento dei tuoi risultati. A questo punto entrano in gioco altre conoscenze e competenze dei professionisti del Data. I dati sono una risorsa altamente preziosa e strategica e, pertanto, è importante implementare pratiche per garantire che l'organizzazione disponga dei dati di cui ha bisogno, quando, come e con la qualità e la sicurezza appropriate. Il Governance dei dati stabilisce la strategia per soddisfare tali esigenze organizzative (esempio: conformarsi al regolamento europeo per la protezione dei dati personali) e la Gestione dei dati implementare pratiche concrete per rispettarle, ad esempio, come evitare silos di dati isolati nei diversi reparti dell'azienda. Altri aspetti che i professionisti dei dati dovrebbero sempre tenere a mente sono: il Qualità (accuratezza, precisione, ecc.), il Sicurezza in tutte le sue dimensioni di integrità, riservatezza e disponibilità; e il Privacy quando si tratta di dati personali. Come posso assicurarmi che non ci siano dati duplicati con valori diversi? Chi può accedere a ciascun dato? o Come posso eliminare o ridurre i rischi di perdita di dati? Queste sono domande a cui i professionisti dei dati devono rispondere correttamente.
Abbiamo presentato le principali competenze e conoscenze informatiche che possono essere richieste in un progetto incentrato sui Dati. Sono molto ampie ed è difficile per la stessa persona raccoglierle tutte in modo sufficientemente approfondito. Pertanto, potrebbe essere conveniente impostare profili professionali diverso. È quello che fa la norma"Profili dei ruoli professionali ICT europei"(https://itprofessionalism.org/about-it-professionalism/competences/ict-profiles/), che distingue tra Data Scientist (Dati Scientist), Specialista dei dati (Specialista di dati) e Responsabile dei dati (Amministratore dei dati). Il primo si concentra soprattutto sull'analisi dei dati, il secondo sugli aspetti di modellazione e governance dei dati e il terzo sulla gestione e la sicurezza dei repository di dati.
Un ultimo aspetto da evidenziare nella professione di Data Science and Engineering è quello progetti possono essere multidisciplinare. Oltre ai profili con le conoscenze e le competenze presentate in questo articolo, in molti progetti è necessario averne altri profili non informatici, in particolare esperti di domini applicativi e matematici/statistici.
I esperti di dominio di applicazione sono le persone che conoscono molto bene il campo di applicazione dei dati (es. esperti di sanità pubblica ed epidemie) e per questo sono coloro che sanno bene cosa interessa misurare e con quali indicatori devono essere prese le decisioni essere fatto. Il loro ruolo all'inizio del progetto è fondamentale per l'identificazione dei bisogni e per conoscere le fonti di dati esistenti. D'altra parte, questi esperti di dominio sono i futuri utenti dei sistemi sviluppati nei progetti Data e, pertanto, è altamente auspicabile che partecipino alla convalida dei risultati. Il matematico/statistico possono contribuire con una conoscenza più approfondita di alcune delle tecniche di analisi per il caso di dati quantitativi numerici.
I dati hanno la loro scienza e la loro ingegneria. La grande importanza che hanno richiede professionisti, in Data Science e Engineering, che sappiano realizzare progetti che aggiungano valore alle organizzazioni e alla società.
Francisco Ruiz (francisco.ruizg@uclm.es)
Mario Piattini (Mario.piattini@uclm.es)


