



Daten, Wissenschaft, Technik und Beruf
von Francisco Ruiz y Mario Piattini (Universitätsprofessoren).
Man sagt, wir erinnern uns nur an Santa Barbara, wenn es donnert. Dies war in Spanien, wie in fast allen Ländern, offensichtlich, als die Regierungen zu Beginn der COVID-Pandemie nicht über angemessene Daten verfügen konnten, um die Situation zu verstehen und fundiertere Entscheidungen zu treffen. Bis die Behörden über Systeme verfügten, die ihnen die Daten in angemessener Form und Zeit zur Verfügung stellten, vergingen mehrere Monate. Und doch wurden seine Glaubwürdigkeit und Genauigkeit nicht allgemein akzeptiert.
Daten, Informationen und Wissen Sie werden oft als Synonyme verwendet, sind es aber nicht. Daten sind die Rohwerte, der Rohstoff. Wenn sie in einen Kontext gestellt werden, werden sie als Information bezeichnet. Schließlich ist Wissen Information in einer Form und einem Kontext, die für bestimmte Zwecke nützlich sind. Beispielsweise sind „195“ Rohdaten, „Luis ist 195 cm groß“ Informationen und „Luis ist eine große Person, weil er 195 cm groß ist“ Wissen.
Die Daten können nützlich sein, um aus ihnen neues Wissen zu generieren und/oder bessere Entscheidungen zu treffen und somit in der Lage zu sein, Kosten zu optimieren, den Bürgern bessere Dienstleistungen anzubieten, den Interessen und Bedürfnissen unserer Nutzer oder Kunden besser gerecht zu werden oder "intern zu verbessern". damit es nach außen wahrgenommen wird“ (Prozessverbesserung). Dank der Entwicklung der Informationstechnologie ist diese Relevanz in den letzten Jahren so weit gewachsen, dass Daten als eine Art neuer Reichtum angesehen werden, für Einzelpersonen, Organisationen oder Länder. Ihre Erfassung und Analyse ist der Schlüssel zu neuen Entdeckungen und vorteilhaften Veränderungen, wie z. B. zur effektiveren Bekämpfung einer Pandemie, zur Kenntnis der Luftqualität in jeder Stadt und jedem Gebiet, um geeignete Maßnahmen zu ergreifen, oder zur Kenntnis der Verkehrssituation in Echtzeit, um Maßnahmen ergreifen zu können Staus schnell vermeiden oder reduzieren. Die Möglichkeiten sind endlos, aber darunter gibt es auch solche mit potenziell negativen Folgen. Aus diesem Grund müssen Datenfachleute von einem starken Verantwortungsbewusstsein und einer professionellen Ethik geprägt sein.
Daten haben ihre Wissenschaft und Technik, aber es gibt keinen Konsens über die Definition von Datenwissenschaft und daher weder in seinen Grenzen mit der Datentechnik.
Zur Verdeutlichung nehmen wir die Worte von Theodore von Kármán, einem angesehenen ungarisch-amerikanischen Physiker und Ingenieur: „lWissenschaftler untersuchen die Welt, wie sie ist, während Ingenieure eine Welt erschaffen, die es noch nie zuvor gegeben hat. Mit anderen Worten, das Ziel der Wissenschaft besteht darin, die Realität zu kennen, während das Ziel der Technik darin besteht, sie durch die Schaffung neuer technologischer Artefakte zu verändern. Angewandt auf die physische Welt können wir ableiten, dass das Studium der Schwarzen Löcher des Universums Wissenschaft ist, während das Entwerfen und Bauen des Teleskops zu ihrer Untersuchung Ingenieurwesen ist. In ähnlicher Weise können wir auf Daten angewendet ableiten, dass Data Science versucht, neues Wissen aus Daten zu gewinnen, während Data Engineering versucht, die Realität mithilfe von Daten zu verändern. Eine ausführlichere und eingeschränktere Definition finden Sie im "Body of Knowledge on Data Management" (Datenmanagement Wissensbestand), erstellt von DAMA (https://www.dama.org), die internationale Vereinigung von Datenmanagement-Experten. DAMA verbindet Data Science mit dem Versuch, die Zukunft vorherzusagen, und definiert es als „Erstellung von Vorhersagemodellen, die in Daten enthaltene Muster untersuchen“. Und dafür „kombiniert es Data Mining, statistische Analyse und maschinelles Lernen mit Datenintegrations- und Modellierungsfähigkeiten“ und „folgt der wissenschaftlichen Methode, um das Wissen zu verbessern, indem es Hypothesen formuliert und verifiziert, Ergebnisse beobachtet und allgemeine Theorien formuliert, die die Ergebnisse erklären“.
Im wirklichen Leben sind die Ziele von Data Science und Engineering oft untrennbar miteinander verbunden, denn um aus Daten neue Erkenntnisse zu gewinnen (Science), müssen zunächst technologische Systeme entworfen und erstellt werden, die diese speichern und richtig verarbeiten (Engineering).
Es kommt sogar häufig vor, dass dieselbe Person manchmal Data Science und anderes Data Engineering betreibt. Aus diesem Grund ist es bequemer, davon zu sprechenDatenwissenschaft und -technik“, einschließlich beider, als die Disziplin, die sich darauf konzentriert, dank Informationstechnologie (IT) einen Wert aus Daten zu ziehen.
Um die Daten nutzen zu können, ist es erforderlich, dass vielfältige Kenntnisse und Fähigkeiten. Die wichtigste internationale Referenz, um zu wissen, was sie sind, ist der ACM-Vorschlag (Verein für Computermaschinen, die renommierteste internationale Vereinigung auf dem Gebiet der Informatik), bekannt als "Computing-Kompetenzen für den Bachelor-Lehrplan für Data Science" (verfügbar in https://www.acm.org/education/curricula-recommendations). Es identifiziert die folgenden elf Wissens- und Kompetenzbereiche (wir belassen die ursprünglichen Akronyme auf Englisch): Analyse und Präsentation von Daten (AP); Künstliche Intelligenz (KI); Big-Data-Systeme (BDS); Computer- und Informatikgrundlagen (CCF); Datenerfassung, -management und -governance (DG); Data-Mining (DM); Datenschutz, Sicherheit, Integrität und Analyse für die Datensicherheit (DP); Maschinelles Lernen (ML); Professionalität (PR); Programmierung, Datenstrukturen und Algorithmen (PDA); und Softwareentwicklung und -wartung (SDM). Einige von ihnen sind anderen Disziplinen innerhalb der Informatik und IT gemeinsam. Andere konzentrieren sich besonders auf die Verantwortlichkeiten von Fachleuten in Data Science and Engineering, wie im Fall der Analyse und Präsentation von Daten; Big-Data-Systeme; Datenerfassung, -management und -governance; und Data-Mining.
Eine weitere relevante Quelle ist die bereits erwähnte DAMA-Vereinigung, die einen auf Datenmanagement fokussierten Ansatz (Teil von Data Engineering) bietet. Die relevanten Kenntnisse und Kompetenzen, die Sie identifiziert haben, werden in die in Abbildung 1 gezeigten Bereiche gruppiert.
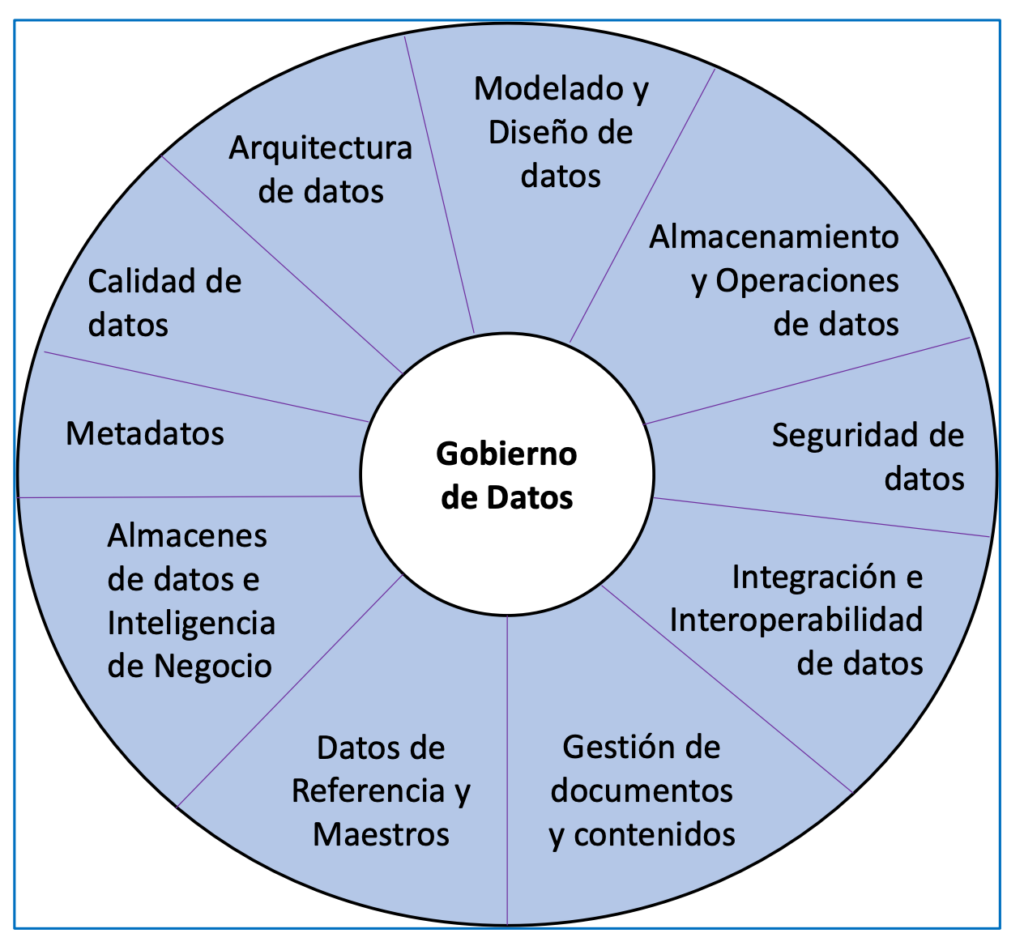
CEPIS (Council of European Professional Informatics Societies) legt fest, dass ein guter Fachmann eine Person ist, die Wissen, Fähigkeiten, Ausbildung, Verantwortung und Ethik kombiniert, um anderen Menschen einen Mehrwert zu bieten.
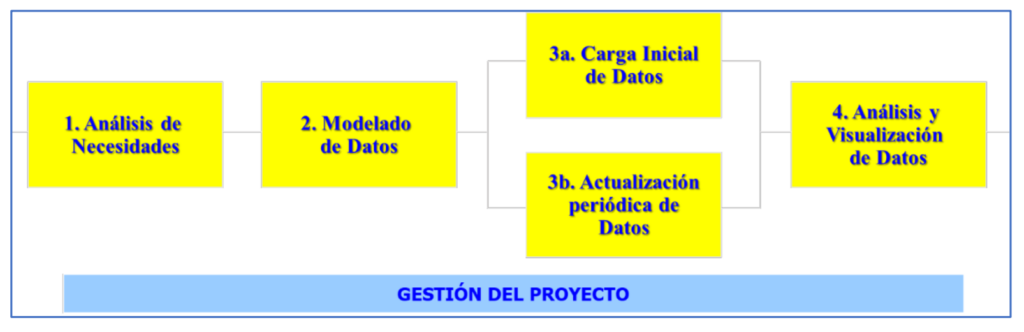
Die beiden oben genannten Sammlungen von Fähigkeiten und Kenntnissen sind ein guter Ausgangspunkt für die Abgrenzung Data Science und Engineering Beruf, deren Zweck es ist, Wert aus den Daten zu extrahieren. Daher muss der Wert eines Fachmanns in dieser Disziplin an seiner Fähigkeit gemessen werden, Wert aus Daten für andere Personen und Organisationen oder für die Gesellschaft im Allgemeinen zu ziehen. Um diesen Wert zu erreichen, führen Datenfachleute Anstrengungen und Projekte durch, deren Endergebnis normalerweise die Schaffung von Informationssystemen ist, die es ermöglichen, Daten zu visualisieren und zu analysieren und daraus neues Wissen zu extrahieren. Diese Projekte werden normalerweise in den in Abbildung 2 gezeigten Phasen durchgeführt.
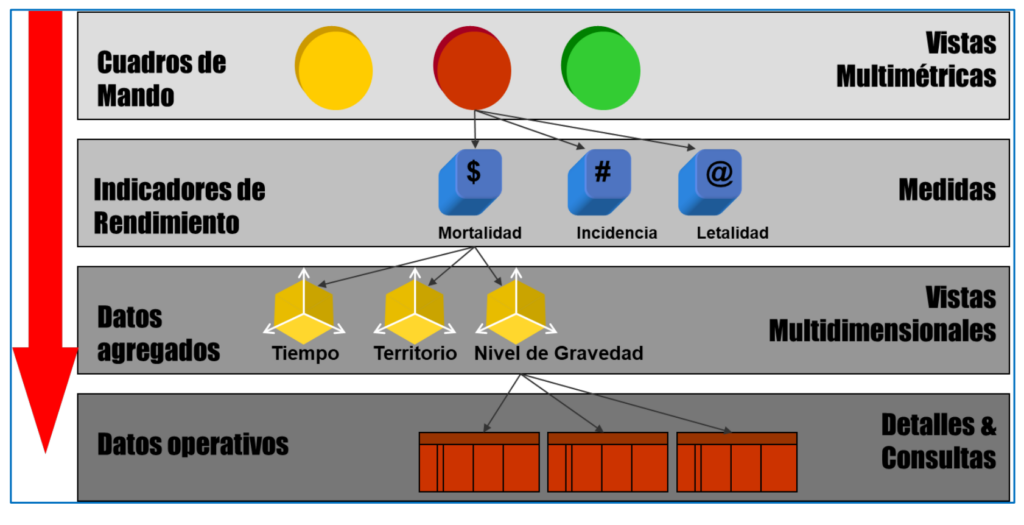
Während der verschiedenen Phasen eines Projekts behandeln Experten Daten und Informationen auf vier verschiedenen Ebenen, wie in Abbildung 3 mit einem Beispiel für Daten aus der COVID-Pandemie dargestellt. Es beginnt mit den rohen Betriebsdaten (Anzahl der Fälle und Todesfälle pro Tag an jedem Ort). Als nächstes müssen Sie die Dimensionen identifizieren, um die Daten zu analysieren, z. B. nach Zeit (wann es passiert), Gebiet (wo es passiert) und Schweregrad (was passiert). Dazu müssen die Daten verarbeitet werden (normalerweise mithilfe von Softwaretools, die bestimmte Algorithmen implementieren), um sie für jede Analysedimension in die entsprechenden Detailebenen zu gruppieren. Beispielsweise im Fall der Zeit nach Tagen, Wochen und Monaten oder im Fall der territorialen Lage nach Orten, Provinzen und autonomen Gemeinschaften. Aus diesen bedarfsgerecht aggregierten Daten können dann die für die Entscheidungsfindung relevanten Kennzahlen errechnet werden, beispielsweise die kumulierte Inzidenz pro Woche pro Bundesland (Anzahl der Fälle pro 100 Einwohner). Schließlich werden die Werte der Indikatoren und andere Daten in der Regel Nicht-Computern über Informationssysteme ("Dashboards" und andere Arten) zur Verfügung gestellt, die die Visualisierung und Analyse der Daten für die Entscheidungsfindung erleichtern. Im https://alarcos.esi.uclm.es/covid19esp/ Ein Beispiel wird mit echten COVID-Daten gezeigt.
Nachfolgend werden einige relevante Aspekte der Phasen von Datenvalorisierungsprojekten dargestellt (Abbildung 2).
Zunächst einmal muss man die Bedürfnisse kennen. In einem Datenprojekt konzentriert sich dies auf die Identifizierung was zu messen ist und wie man es misst entsprechend und finden Sie daraus die Quellen wo wir die dafür notwendigen Daten erhalten können.
In der zweiten Stufe wird ein wichtiger Aspekt für die Arbeit mit Daten angesprochen: Ihnen eine angemessene Struktur und Form zu geben, um sie auf Computern speichern und alles damit machen zu können, was wir wollen. Diese Aufgabe kann für den Erfolg eines Datenprojekts genauso relevant sein wie „die Baupläne richtig zu machen“ für ein Bauprojekt. In dieser Hinsicht ist der generische Architekturbegriff (definiert in der Norm ISO 42010) hilfreich. Und so kam es dass der 'Datenarchitektur' Legt die Elemente oder Abteilungen fest, in denen wir sie trennen (Tabellen, Dateien usw.) und die Beziehungen zwischen diesen Elementen. Es ist auch notwendig, die interne Struktur jedes Fachs (welche spezifischen Daten es speichert) und die Art oder Art (Anzahl, Datum, Text, Audio, Video, Dokument, ...) jeder spezifischen Daten gut zu definieren. Das Datenmodellierung Es besteht darin, „Blaupausen“ mit einer Architektur und Datenstruktur zu erstellen, die für die Anforderungen des Projekts geeignet sind. Diese Blaupausen können in Form von Entity-Relationship-, relationalen oder multidimensionalen Schemata ausgedrückt werden.
Von Rohdaten zu für die Analyse vorbereiteten Daten zu gelangen, kann eine ziemlich komplexe Aufgabe sein. Ähnlich verhält es sich mit Wasser, das, um für den menschlichen Verzehr geeignet zu sein, verschiedene Umwandlungen von der Quelle, aus der es stammt, durchlaufen muss und für das auch verschiedene Arten von Rohren und Rohren gebaut werden müssen. Daher ist es notwendig, alle Quellen der Originaldaten aus bereits verfügbaren Computerdateien mit einer klaren Struktur (CSV, Excel usw.).) auf Daten in unstrukturierten Formaten wie dem Internet oder sozialen Netzwerken. Das ETL-Prozesse, zum Extrahieren, Transformieren und Laden, besteht aus: i) Herunterladen der Rohdaten aus den Originalquellen; ii) sie in geeignete und homogene Formate und Strukturen umzuwandeln; und iii) sie in ein Repository zu integrieren oder Datenlager, basierend auf der zuvor etablierten Datenarchitektur. Für ETL können Sie traditionelle Technologien (wie SQL) verwenden, aber Sie können produktiver sein, wenn Sie andere verwenden, die speziell dafür entwickelt wurden (Power Query, Big Query usw.). Eine Alternative in den letzten Jahren ist die Verwendung von a Datensee (Datensee). Es handelt sich um eine Technologie, die die Erstellung eines integrierten Datenspeichers vermeidet und ihn durch eine Sammlung heterogener Daten ersetzt, die ihr ursprüngliches Format beibehalten, aber im selben Computersystem gespeichert werden. Um einen gemeinsamen und integrierten Zugang zu gewährleisten, ist dies erforderlich Metadaten (Daten über Daten).
Ein Bedürfnis des Data Science and Engineering-Experten, das stark mit der Datenmodellierung zusammenhängt, ist das Wissen, wie man damit umgeht Technologie Rechnen für Daten speichern und verarbeiten effizient und effektiv.
Ohne sie ist es unmöglich, die dritte Phase der Datenvalorisierungsprojekte durchzuführen (Abbildung 2). Das oben erwähnte Datenrepository kann mit zwei Arten von Technologien durchgeführt werden: Datenverwaltungssysteme Datenbanken (traditionelle relationale wie ORACLE, MySQL usw.; oder nicht-relationale wie MongoDB) und Tools für Big Data (Hadoop, Elasticsearch usw.). Letztere ersetzen erstere, wenn es notwendig ist, mit riesigen Datenmengen zu arbeiten, und ermöglichen es, die Herausforderungen des Datenmanagements anzugehen, die als die 7 Vs von Big Data bekannt sind: Volumen, Geschwindigkeit, Vielfalt, Wahrhaftigkeit, Machbarkeit, Visualisierung und Wert der Daten. Eine weitere Option, oft gepaart mit Big Data, sind die bereits erwähnten Data-Lake-Technologien.
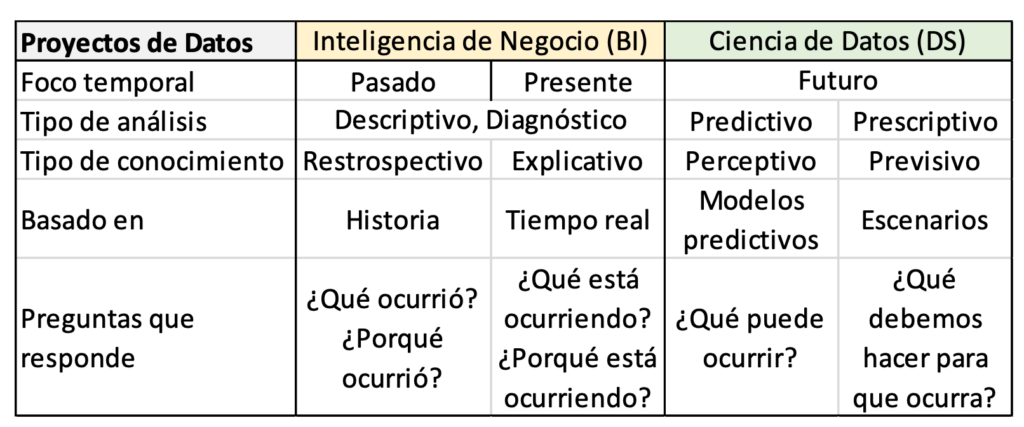
Nachdem das Repository oder sein Äquivalent erstellt und gefüllt wurde, erfolgt in der vierten Phase die tatsächliche Gewinnung von Wert aus den Daten durch deren Analyse und Visualisierung. Dazu ist es zunächst erforderlich, die Arten von zu kennen Datenanalyse Dies ist je nach Art der Fragen, die Sie beantworten möchten, möglich: beschreibend (was ist passiert?), Diagnose (Warum ist es passiert?), vorausschauend (Was wird wahrscheinlich als nächstes passieren?) und vorgeschrieben (Was ist die beste Option, um zu folgen?). Jede Art von Analyse basiert auf einer Art von mathematischen (Statistik, numerische Methoden) oder Computertechniken (maschinelles Lernen, Data Mining usw.). Es ist wichtig, die Art der Analyse und die spezifischen Techniken zu kennen, die für jede Situation nützlich sind, da dies die Werkzeuge bestimmt, die wir dafür verwenden können. Um beispielsweise herauszufinden, ob das Virus häufiger in Städten oder auf dem Land vorkommt, kann eine deskriptive Analyse mit klassischen Basisstatistiken durchgeführt werden. Um zu wissen, wann die nächste Virenwelle voraussichtlich auftritt, können wir stattdessen maschinelles Lernen und/oder Data Mining einsetzen. Je nach Art der durchgeführten Analyse kann zwischen Initiativen zur Datenvalorisierung unterschieden werden Data Science-Projekte o Business-Intelligence-Projekte (BI, Geschäftsanalytik). Das Wort „Geschäft“ in letzterem bezieht sich darauf, das zu tun, was für eine Organisation richtig ist, um ihre Ziele zu erreichen. Tabelle 1 fasst die Hauptunterschiede zwischen ihnen zusammen. Diese Trennung ist in der Realität oft nicht vorhanden, da die Projekte verschiedene Analysearten kombinieren, sowohl Data Science als auch Business Intelligence. Es kommt auch häufig vor, dass die Bedürfnisse und Arten der Analyse a priori nicht vollständig bekannt sind oder sich je nach Entwicklung des Projekts ändern.
Maschinelles Lernen, oder maschinelles Lernen (Maschinelles Lernen) ist eine Gruppe von Techniken, die verwendet werden, um Muster in Daten zu entdecken und Vorhersagen zu treffen. Beinhaltet Entscheidungsbäume, lineare Regression, Clustering (Clustering) und neuronale Netze, unter anderem. Sein Name kommt von der Tatsache, dass einige von ihnen, im Fall von neuronalen Netzen, darauf basieren, wie das menschliche Gehirn lernt. Es gibt viele Softwaretools, die die Umsetzung erleichtern, wie TensorFlow, Cloud AutoML oder Azure ML.
Name Data Mining Hinweise auf Ähnlichkeit mit traditionellem Bergbau. In der Tat verwendet Physical Mining Techniken, um einen kleinen wertvollen Teil zu extrahieren, indem riesige Mengen an Erde aus dem Boden verarbeitet werden, und der zweite extrahiert wertvolle Informationen durch die Verarbeitung großer Datenmengen. Es gibt mehrere Technologien für das Data Mining. Einige sind spezialisierte Tools, wie RapidMiner. Es gibt auch Programmiersprachen wie R und DAX. Andere sind für allgemeine Zwecke gedacht, wie die Sprache Python. Ein Sonderfall ist die Process-Mining des Geschäfts, sehr relevant für die transformación digital von Organisationen, da sie Daten analysiert, die alles Relevante widerspiegeln, was in den internen Prozessen einer Organisation (Verkauf, Lagerung, Herstellung, Patientenversorgung usw.) ) die Art und Weise, wie die Prozesse durchgeführt werden.
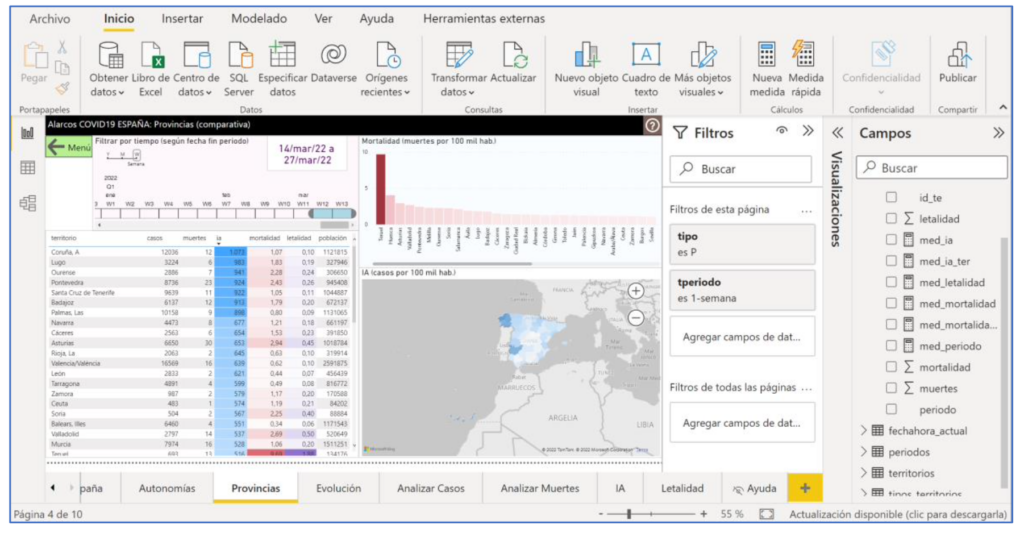
Als Ergänzung zur Datenanalyse beinhalten viele Projekte eine ordnungsgemäße Datenvisualisierung (obere Reihe in Abbildung 3). Das Datenvisualisierung Es kann sehr wichtig sein, einen Mehrwert zu schaffen, indem es die Konsultation und das Verständnis der für die Entscheidungsfindung Verantwortlichen erleichtert. Es gibt spezialisierte Softwaretools, die es ermöglichen, Systeme zu erhalten, bei denen die Benutzerschnittstelle dank der Verwendung vordefinierter Interaktionsmuster hochgradig visuell und interaktiv ist. Dies ist der Fall bei Tools wie Tableau oder Power BI (Abbildung 4 zeigt ihre Verwendung zum Erstellen des Beispiels mit COVID-Daten). Einige Tools, wie Power BI, umfassen Funktionen für alle Phasen von Datenprojekten, vom Herunterladen von Daten aus Quellen bis hin zu Analysen verschiedener Art und Visualisierung. Sie sind als ABI-Plattformen bekannt (Analytik und Business Intelligence).
Sobald ein Datenprojekt abgeschlossen ist (alle Phasen von Abbildung 2 abgeschlossen), treten Sie in das ein Ausbeutung Ihrer Ergebnisse. An dieser Stelle kommen andere Kenntnisse und Fähigkeiten von Datenprofis ins Spiel. Daten sind ein äußerst wertvolles und strategisches Gut und daher ist es wichtig, Praktiken zu implementieren, um sicherzustellen, dass die Organisation über die Daten verfügt, die sie benötigt, wann, wie und mit der angemessenen Qualität und Sicherheit. Das Datenamt legt die Strategie fest, um diese organisatorischen Anforderungen zu erfüllen (Beispiel: Einhaltung der europäischen Verordnung zum Schutz personenbezogener Daten) und die Datenmanagement Implementieren Sie konkrete Praktiken, um sie einzuhalten, zum Beispiel, wie isolierte Datensilos in den verschiedenen Abteilungen des Unternehmens vermieden werden können. Andere Aspekte, die Datenprofis immer im Auge behalten sollten, sind: die Qualität (Genauigkeit, Präzision usw.), die Sicherheit in all ihren Dimensionen der Integrität, Vertraulichkeit und Verfügbarkeit; und die Datenschutz wenn es um personenbezogene Daten geht. Wie stelle ich sicher, dass es keine doppelten Daten mit unterschiedlichen Werten gibt? Wer kann auf die einzelnen Daten zugreifen? o Wie eliminiere oder reduziere ich das Risiko eines Datenverlusts? Das sind Fragen, die Datenprofis richtig beantworten müssen.
Wir haben die wichtigsten Computerfähigkeiten und -kenntnisse vorgestellt, die in einem auf Daten ausgerichteten Projekt erforderlich sein können. Sie sind sehr breit gefächert und es ist für dieselbe Person schwierig, sie alle in ausreichender Tiefe zu erfassen. Daher kann die Einstellung bequem sein professionelle Profile anders. Es ist, was die Norm tut "Europäische IKT-Berufsrollenprofile"(https://itprofessionalism.org/about-it-professionalism/competences/ict-profiles/), der zwischen Data Scientist (Daten Scientist), Datenspezialist (Datenspezialist) und Datenmanager (Datenadministrator). Der erste konzentriert sich vor allem auf die Datenanalyse, der zweite auf Datenmodellierung und Governance-Aspekte und der dritte auf das Management und die Sicherheit von Datenbeständen.
Ein letzter Aspekt, der im Beruf Data Science and Engineering hervorzuheben ist, ist dieser Projekte sein kann multidisziplinär. Zusätzlich zu Profilen mit den in diesem Artikel vorgestellten Kenntnissen und Fähigkeiten sind in vielen Projekten andere erforderlich Nicht-Computer-Profile, insbesondere Anwendungsdomänenexperten und Mathematiker/Statistiker.
Die Domänenexperten Anwendungsbereich sind die Personen, die den Anwendungsbereich der Daten sehr gut kennen (z. B. Experten für öffentliche Gesundheit und Epidemien) und aus diesem Grund genau wissen, was zu messen ist und mit welchen Indikatoren Entscheidungen getroffen werden müssen gemacht sein. Ihre Rolle zu Beginn des Projekts ist der Schlüssel zur Bedarfsermittlung und zur Kenntnis der vorhandenen Datenquellen. Andererseits sind diese Domänenexperten die zukünftigen Nutzer der in den Data-Projekten entwickelten Systeme und daher ist es sehr wünschenswert, dass sie an der Validierung der Ergebnisse teilnehmen. Das mathematisch/statistisch sie können mit einem tieferen Wissen über einige der Analysetechniken für den Fall numerischer quantitativer Daten beitragen.
Daten haben ihre Wissenschaft und ihre Technik. Die große Bedeutung, die sie haben, erfordert Experten in Data Science und Engineering, die wissen, wie man Projekte mit Mehrwert für Organisationen und die Gesellschaft durchführt.
Francisco Ruiz (francisco.ruizg@uclm.es)
Mario Piattini (Mario.piattini@uclm.es)


